-
大佬,互换个友链, 已添加您了
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
-
博主已经添加了名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
} 名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
知了小站
不怕学问浅,就怕志气短。
搜索到
74
篇与
的结果
-
 EL-ADMIN v2.3 发布,新增在线用户管理,多项优化 EL-ADMIN 是基于 Spring Boot 2.1.0 、 Jpa、 Spring Security、Redis、Vue的前后端分离的权限管理系统,项目采用按功能分模块开发方式, 权限控制采用 RBAC 方式,前端菜单动态路由。新版更新内容如下:后端代码优化,优化大量Idea警告,代码更严谨 #134加入实体基类(BaseEntity)、DTO基类(BaseDTO),按需继承 #137新增基于Redis的在线用户管理,可强制下线用户 #6新增退出登录接口,退出登录后Token不再有效图形验证码更换,由随机验证码模式,改为算术验证日志管理加入浏览器字段,获取Ip地址优化,局域网内支持获取到主机地址菜单与权限调整,权限管理作为按钮存入菜单表增加匿名访问注解,扩展PreAuthorize 匿名注解 #159自定义权限校验,@PreAuthorize("@el.check('dept:list')"),根据个人习惯可自行选择代码生成器优化,前后端默认添加导出功能,input时间组件自动判定自定义异步线程池(重写spring默认线程池),使用自定义线程池执行定时任务,避免程序OOM免费图床优化,通过MD5判断图片是否重复上传,如果图片存在则返回历史图片前端简化数据字典的使用,由混入改为全局,支持单组件内多字典同时使用 #37存储管理增加图片路径提示和图片预览 #40树形表格更换,采用 element-ui 自带的树形表格组件修复解决Gson找不到包的bug #141解决ip2region.db路径不正确的问题 #1462.3版本指南:https://docs.auauz.net/#/sjzn预览地址:https://auauz.net/项目源码 后端源码前端源码Githubhttps://github.com/elunez/eladminhttps://github.com/elunez/eladmin-web码云https://gitee.com/elunez/eladminhttps://gitee.com/elunez/eladmin-web
EL-ADMIN v2.3 发布,新增在线用户管理,多项优化 EL-ADMIN 是基于 Spring Boot 2.1.0 、 Jpa、 Spring Security、Redis、Vue的前后端分离的权限管理系统,项目采用按功能分模块开发方式, 权限控制采用 RBAC 方式,前端菜单动态路由。新版更新内容如下:后端代码优化,优化大量Idea警告,代码更严谨 #134加入实体基类(BaseEntity)、DTO基类(BaseDTO),按需继承 #137新增基于Redis的在线用户管理,可强制下线用户 #6新增退出登录接口,退出登录后Token不再有效图形验证码更换,由随机验证码模式,改为算术验证日志管理加入浏览器字段,获取Ip地址优化,局域网内支持获取到主机地址菜单与权限调整,权限管理作为按钮存入菜单表增加匿名访问注解,扩展PreAuthorize 匿名注解 #159自定义权限校验,@PreAuthorize("@el.check('dept:list')"),根据个人习惯可自行选择代码生成器优化,前后端默认添加导出功能,input时间组件自动判定自定义异步线程池(重写spring默认线程池),使用自定义线程池执行定时任务,避免程序OOM免费图床优化,通过MD5判断图片是否重复上传,如果图片存在则返回历史图片前端简化数据字典的使用,由混入改为全局,支持单组件内多字典同时使用 #37存储管理增加图片路径提示和图片预览 #40树形表格更换,采用 element-ui 自带的树形表格组件修复解决Gson找不到包的bug #141解决ip2region.db路径不正确的问题 #1462.3版本指南:https://docs.auauz.net/#/sjzn预览地址:https://auauz.net/项目源码 后端源码前端源码Githubhttps://github.com/elunez/eladminhttps://github.com/elunez/eladmin-web码云https://gitee.com/elunez/eladminhttps://gitee.com/elunez/eladmin-web -
Java 8:一文掌握 Lambda 表达式 本文将介绍 Java 8 新增的 Lambda 表达式,包括 Lambda 表达式的常见用法以及方法引用的用法,并对 Lambda 表达式的原理进行分析,最后对 Lambda 表达式的优缺点进行一个总结。1. 概述Java 8 引入的 Lambda 表达式的主要作用就是简化部分匿名内部类的写法。能够使用 Lambda 表达式的一个重要依据是必须有相应的函数接口。所谓函数接口,是指内部有且仅有一个抽象方法的接口。Lambda 表达式的另一个依据是类型推断机制。在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。2. 常见用法2.1 无参函数的简写无参函数就是没有参数的函数,例如 Runnable 接口的 run() 方法,其定义如下:@FunctionalInterface public interface Runnable { public abstract void run(); }在 Java 7 及之前版本,我们一般可以这样使用:new Thread(new Runnable() { @Override public void run() { System.out.println("Hello"); System.out.println("Jimmy"); } }).start();从 Java 8 开始,无参函数的匿名内部类可以简写成如下方式:() -> { 执行语句 }这样接口名和函数名就可以省掉了。那么,上面的示例可以简写成:new Thread(() -> { System.out.println("Hello"); System.out.println("Jimmy"); }).start();当只有一条语句时,我们还可以对代码块进行简写,格式如下:() -> 表达式注意这里使用的是表达式,并不是语句,也就是说不需要在末尾加分号。那么,当上面的例子中执行的语句只有一条时,可以简写成这样:new Thread(() -> System.out.println("Hello")).start();2.2 单参函数的简写单参函数是指只有一个参数的函数。例如 View 内部的接口 OnClickListener 的方法 onClick(View v),其定义如下:public interface OnClickListener { /** * Called when a view has been clicked. * * @param v The view that was clicked. */ void onClick(View v); }在 Java 7 及之前的版本,我们通常可能会这么使用:view.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { v.setVisibility(View.GONE); } });从 Java 8 开始,单参函数的匿名内部类可以简写成如下方式:([类名 ]变量名) -> { 执行语句 }其中类名是可以省略的,因为 Lambda 表达式可以自己推断出来。那么上面的例子可以简写成如下两种方式:view.setOnClickListener((View v) -> { v.setVisibility(View.GONE); }); view.setOnClickListener((v) -> { v.setVisibility(View.GONE); });单参函数甚至可以把括号去掉,官方也更建议使用这种方式:变量名 -> { 执行语句 }那么,上面的示例可以简写成:view.setOnClickListener(v -> { v.setVisibility(View.GONE); });当只有一条语句时,依然可以对代码块进行简写,格式如下:([类名 ]变量名) -> 表达式类名和括号依然可以省略,如下:变量名 -> 表达式那么,上面的示例可以进一步简写成:view.setOnClickListener(v -> v.setVisibility(View.GONE));2.3 多参函数的简写多参函数是指具有两个及以上参数的函数。例如,Comparator 接口的 compare(T o1, T o2) 方法就具有两个参数,其定义如下:@FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); }在 Java 7 及之前的版本,当我们对一个集合进行排序时,通常可以这么写:List<Integer> list = Arrays.asList(1, 2, 3); Collections.sort(list, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } });从 Java 8 开始,多参函数的匿名内部类可以简写成如下方式:([类名1 ]变量名1, [类名2 ]变量名2[, ...]) -> { 执行语句 }同样类名可以省略,那么上面的例子可以简写成:Collections.sort(list, (Integer o1, Integer o2) -> { return o1.compareTo(o2); }); Collections.sort(list, (o1, o2) -> { return o1.compareTo(o2); });当只有一条语句时,依然可以对代码块进行简写,格式如下:([类名1 ]变量名1, [类名2 ]变量名2[, ...]) -> 表达式此时类名也是可以省略的,但括号不能省略。如果这条语句需要返回值,那么 return 关键字是不需要写的。因此,上面的示例可以进一步简写成:Collections.sort(list, (o1, o2) -> o1.compareTo(o2));最后呢,这个示例还可以简写成这样:Collections.sort(list, Integer::compareTo);咦,这是什么特性?这就是我们下面要讲的内容:方法引用。3. 方法引用方法引用也是一个语法糖,可以用来简化开发。在我们使用 Lambda 表达式的时候,如果“->”的右边要执行的表达式只是调用一个类已有的方法,那么就可以用「方法引用」来替代 Lambda 表达式。方法引用可以分为 4 类:引用静态方法;引用对象的方法;引用类的方法;引用构造方法。下面按照这 4 类分别进行阐述。3.1 引用静态方法当我们要执行的表达式是调用某个类的静态方法,并且这个静态方法的参数列表和接口里抽象函数的参数列表一一对应时,我们可以采用引用静态方法的格式。假如 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> 类名.静态方法名([变量1, 变量2, ...])我们可以简写成如下格式:类名::静态方法名注意这里静态方法名后面不需要加括号,也不用加参数,因为编译器都可以推断出来。下面我们继续使用 2.3 节的示例来进行说明。首先创建一个工具类,代码如下:public class Utils { public static int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }注意这里的 compare() 函数的参数和 Comparable 接口的 compare() 函数的参数是一一对应的。然后一般的 Lambda 表达式可以这样写:Collections.sort(list, (o1, o2) -> Utils.compare(o1, o2));如果采用方法引用的方式,可以简写成这样:Collections.sort(list, Utils::compare);3.2 引用对象的方法当我们要执行的表达式是调用某个对象的方法,并且这个方法的参数列表和接口里抽象函数的参数列表一一对应时,我们就可以采用引用对象的方法的格式。假如 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> 对象引用.方法名([变量1, 变量2, ...])我们可以简写成如下格式:对象引用::方法名下面我们继续使用 2.3 节的示例来进行说明。首先创建一个类,代码如下:public class MyClass { public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }当我们创建一个该类的对象,并在 Lambda 表达式中使用该对象的方法时,一般可以这么写:MyClass myClass = new MyClass(); Collections.sort(list, (o1, o2) -> myClass.compare(o1, o2));注意这里函数的参数也是一一对应的,那么采用方法引用的方式,可以这样简写:MyClass myClass = new MyClass(); Collections.sort(list, myClass::compare);此外,当我们要执行的表达式是调用 Lambda 表达式所在的类的方法时,我们还可以采用如下格式:this::方法名例如我在 Lambda 表达式所在的类添加如下方法:private int compare(Integer o1, Integer o2) { return o1.compareTo(o2); }当 Lambda 表达式使用这个方法时,一般可以这样写:Collections.sort(list, (o1, o2) -> compare(o1, o2));如果采用方法引用的方式,就可以简写成这样:Collections.sort(list, this::compare);3.3 引用类的方法引用类的方法所采用的参数对应形式与上两种略有不同。如果 Lambda 表达式的“->”的右边要执行的表达式是调用的“->”的左边第一个参数的某个实例方法,并且从第二个参数开始(或无参)对应到该实例方法的参数列表时,就可以使用这种方法。可能有点绕,假如我们的 Lambda 表达式符合如下格式:(变量1[, 变量2, ...]) -> 变量1.实例方法([变量2, ...])那么我们的代码就可以简写成:变量1对应的类名::实例方法名还是使用 2.3 节的例子, 当我们使用的 Lambda 表达式是这样时:Collections.sort(list, (o1, o2) -> o1.compareTo(o2));按照上面的说法,就可以简写成这样:Collections.sort(list, Integer::compareTo);3.4 引用构造方法当我们要执行的表达式是新建一个对象,并且这个对象的构造方法的参数列表和接口里函数的参数列表一一对应时,我们就可以采用「引用构造方法」的格式。假如我们的 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> new 类名([变量1, 变量2, ...])我们就可以简写成如下格式:类名::new下面举个例子说明一下。Java 8 引入了一个 Function 接口,它是一个函数接口,部分代码如下:@FunctionalInterface public interface Function<T, R> { /** * Applies this function to the given argument. * * @param t the function argument * @return the function result */ R apply(T t); // 省略部分代码 }我们用这个接口来实现一个功能,创建一个指定大小的 ArrayList。一般我们可以这样实现:Function<Integer, ArrayList> function = new Function<Integer, ArrayList>() { @Override public ArrayList apply(Integer n) { return new ArrayList(n); } }; List list = function.apply(10);使用 Lambda 表达式,我们一般可以这样写:Function<Integer, ArrayList> function = n -> new ArrayList(n);使用「引用构造方法」的方式,我们可以简写成这样:Function<Integer, ArrayList> function = ArrayList::new;4. 自定义函数接口自定义函数接口很容易,只需要编写一个只有一个抽象方法的接口即可,示例代码:@FunctionalInterface public interface MyInterface<T> { void function(T t); }上面代码中的 @FunctionalInterface 是可选的,但加上该注解编译器会帮你检查接口是否符合函数接口规范。就像加入 @Override 注解会检查是否重写了函数一样。5. 实现原理经过上面的介绍,我们看到 Lambda 表达式只是为了简化匿名内部类书写,看起来似乎在编译阶段把所有的 Lambda 表达式替换成匿名内部类就可以了。但实际情况并非如此,在 JVM 层面,Lambda 表达式和匿名内部类其实有着明显的差别。5.1 匿名内部类的实现匿名内部类仍然是一个类,只是不需要我们显式指定类名,编译器会自动为该类取名。比如有如下形式的代码:public class LambdaTest { public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { System.out.println("Hello World"); } }).start(); } }编译之后将会产生两个 class 文件:LambdaTest.class LambdaTest$1.class使用 javap -c LambdaTest.class 进一步分析 LambdaTest.class 的字节码,部分结果如下:public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/Thread 3: dup 4: new #3 // class com/example/myapplication/lambda/LambdaTest$1 7: dup 8: invokespecial #4 // Method com/example/myapplication/lambda/LambdaTest$1."<init>":()V 11: invokespecial #5 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V 14: invokevirtual #6 // Method java/lang/Thread.start:()V 17: return可以发现在 4: new #3 这一行创建了匿名内部类的对象。5.2 Lambda 表达式的实现接下来我们将上面的示例代码使用 Lambda 表达式实现,代码如下:public class LambdaTest { public static void main(String[] args) { new Thread(() -> System.out.println("Hello World")).start(); } }此时编译后只会产生一个文件 LambdaTest.class,再来看看通过 javap 对该文件反编译后的结果:public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/Thread 3: dup 4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable; 9: invokespecial #4 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V 12: invokevirtual #5 // Method java/lang/Thread.start:()V 15: return从上面的结果我们发现 Lambda 表达式被封装成了主类的一个私有方法,并通过 invokedynamic 指令进行调用。因此,我们可以得出结论:Lambda 表达式是通过 invokedynamic 指令实现的,并且书写 Lambda 表达式不会产生新的类。既然 Lambda 表达式不会创建匿名内部类,那么在 Lambda 表达式中使用 this 关键字时,其指向的是外部类的引用。6. 优缺点优点:可以减少代码的书写,减少匿名内部类的创建,节省内存占用。使用时不用去记忆所使用的接口和抽象函数。缺点:易读性较差,阅读代码的人需要熟悉 Lambda 表达式和抽象函数中参数的类型。不方便进行调试。参考关于Java Lambda表达式看这一篇就够了详解Java8特性之方法引用原文链接:https://blog.csdn.net/u013541140/article/details/102710138
-
RESTful 规范 Api 最佳设计实践 RESTful是目前比较流行的接口路径设计规范,基于HTTP,一般使用JSON方式定义,通过不同HttpMethod来定义对应接口的资源动作,如:新增(POST)、删除(DELETE)、更新(PUT、PATCH)、查询(GET)等。路径设计在RESTful设计规范内,每一个接口被认为是一个资源请求,下面我们针对每一种资源类型来看下API路径设计。路径设计的注意事项如下所示:资源名使用复数资源名使用名词路径内不带特殊字符避免多级URL新增资源请求方式示例路径POSThttps://api.yuqiyu.com/v1/users新增资源使用POST方式来定义接口,新增资源数据通过RequestBody方式进行传递,如下所示:curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "恒宇少年", "age": 25, "address": "山东济南" }'新增资源后接口应该返回该资源的唯一标识,比如:主键值。{ "id" : 1, "name" : "恒宇少年" }通过返回的唯一标识来操作该资源的其他数据接口。删除资源请求方式示例路径备注DELETEhttps://api.yuqiyu.com/v1/users批量删除资源DELETEhttps://api.yuqiyu.com/v1/users/{id}删除单个资源删除资源使用DELETE方式来定义接口。根据主键值删除单个资源curl -X DELETE https://api.yuqiyu.com/v1/users/1将资源的主键值通过路径的方式传递给接口。删除多个资源curl -X DELETE -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "userIds": [ 1, 2, 3 ] }'删除多个资源时通过RequestBody方式进行传递删除条件的数据列表,上面示例中通过资源的主键值集合作为删除条件,当然也可以通过资源的其他元素作为删除的条件,比如:name更新资源请求方式示例路径备注PUThttps://api.yuqiyu.com/v1/users/{id}更新单个资源的全部元素PATCHhttps://api.yuqiyu.com/v1/users/{id}更新单个资源的部分元素在更新资源数据时使用PUT方式比较多,也是比较常见的,如下所示:curl -X PUT -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users/1 -d '{ "name": "恒宇少年", "age": 25, "address": "山东济南" }'查询单个资源请求方式示例路径备注GEThttps://api.yuqiyu.com/v1/users/{id}查询单个资源GEThttps://api.yuqiyu.com/v1/users?name={name}非唯一标识查询资源唯一标识查询单个资源curl https://api.yuqiyu.com/v1/users/1通过唯一标识查询资源时,使用路径方式传递标识值,体现出层级关系。非唯一标识查询单个资源curl https://api.yuqiyu.com/v1/users?name=恒宇少年查询资源数据时不仅仅都是通过唯一标识值作为查询条件,也可能会使用资源对象内的某一个元素作为查询条件。分页查询资源请求方式示例路径GEThttps://api.yuqiyu.com/v1/users?page=1&size=20分页查询资源时,我们一般需要传递两个参数作为分页的条件,page代表了当前分页的页码,size则代表了每页查询的资源数量。curl https://api.yuqiyu.com/v1/users?page=1&size=20如果分页时需要传递查询条件,可以继续追加请求参数。https://api.yuqiyu.com/v1/users?page=1&size=20&name=恒宇少年动作资源有时我们需要有动作性的修改某一个资源的元素内容,比如:重置密码。请求方式示例路径备注POSThttps://api.yuqiyu.com/v1/users/{id}/actions/forget-password-用户的唯一标识在请求路径中进行传递,而修改后的密码通过RequestBody方式进行传递,如下所示:curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users/1/actions/forget-password -d '{ "newPassword": "123456" }'版本号版本号是用于区分Api接口的新老标准,比较流行的分别是接口路径、头信息这两种方式传递。接口路径方式我们在部署接口时约定不同版本的请求使用HTTP代理转发到对应版本的接口网关,常用的请求转发代理比如使用:Nginx等。这种方式存在一个弊端,如果多个版本同时将请求转发到同一个网关时,会导致具体版本的请求转发失败,我们访问v1时可能会转发到v2,这并不是我们期望的结果,当然可以在网关添加一层拦截器,通过提取路径上班的版本号来进行控制转发。# v1版本的请求 curl https://api.yuqiyu.com/v1/users/1 # v2版本的请求 curl https://api.yuqiyu.com/v2/users/1头信息方式我们可以将访问的接口版本通过HttpHeader的方式进行传递,在网关根据提取到的头信息进行控制转发到对应版本的服务,这种方式资源路径的展现形式不会因为版本的不同而变化。# v1版本的请求 curl -H 'Accept-Version:v1' https://api.yuqiyu.com/users/1 # v2版本的请求 curl -H 'Access-Version: v2' https://api.yuqiyu.com/users/1这两个版本的请求可能请求参数、返回值都不一样,但是请求的路径是一样的。版本头信息的Key可以根据自身情况进行定义,推荐使用Accpet形式,详见 Versioning REST Services。状态码在RESTful设计规范内我们需要充分的里面HttpStatus请求的状态码来判断一个请求发送状态,本次请求是否有效,常见的HttpStatus状态码如下所示:状态码发生场景200请求成功201新资源创建成功204没有任何内容返回400传递的参数格式不正确401没有权限访问403资源受保护404访问的路径不正确405访问方式不正确,GET请求使用POST方式访问410地址已经被转移,不可用415要求接口返回的格式不正确,比如:客户端需要JSON格式,接口返回的是XML429客户端请求次数超过限额500访问的接口出现系统异常503服务不可用,服务一般处于维护状态针对不同的状态码我们要做出不同的反馈,下面我们先来看一个常见的参数异常错误响应设计方式:# 发起请求 curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "", "age": 25, "address": "山东济南" }' # 响应状态 HttpStatus 200 # 响应内容 { "code": "400", "message": "用户名必填." }在服务端我们可以控制不同状态码、不同异常的固定返回格式,不应该将所有的异常请求都返回200,然后对应返回错误,正确的方式:# 发起请求 curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "", "age": 25, "address": "山东济南" }' # 响应状态 HttpStatus 400 # 响应内容 { "error": "Bad Request", "message": "用户名必填." }响应格式接口的响应格式应该统一。每一个请求成功的接口返回值外层格式应该统一,在服务端可以采用实体方式进行泛型返回。如下所示:/** * Api统一响应实体 * {@link #data } 每个不同的接口响应的数据内容 * {@link #code } 业务异常响应状态码 * {@link #errorMsg} 业务异常消息内容 * {@link #timestamp} 接口响应的时间戳 * * @author 恒宇少年 - 于起宇 */ @Data public class ApiResponse<T> implements Serializable { private T data; private String code; private String errorMsg; private Long timestamp; }data由于每一个API的响应数据类型不一致,所以在上面采用的泛型的泛型进行返回,data可以返回任意类型的数据。code业务逻辑异常码,比如:USER_NOT_FOUND(用户不存在)这是接口的约定errorMsg对应code值得描述。timestamp请求响应的时间戳总结RESTful是API的设计规范,并不是所有的接口都应该遵循这一套规范来设计,不过我们在设计初期更应该规范性,这样我们在后期阅读代码时根据路径以及请求方式就可以了解接口的主要完成的工作。作者:恒宇少年链接:https://www.jianshu.com/p/35f1d3222cde来源:简书
-
Spring boot 整合 FreeMarker 实现代码生成功能 在我们开发一个新的功能的时候,会根据表创建Entity,Controller,Service,Repository等代码,其中很多步骤都是重复的,并且特别繁琐。这个时候就需要一个代码生成器帮助我们解决这个问题从而提高工作效率,让我们更致力于业务逻辑。设计原理在我们安装数据库后会有几个默认的数据库,其中information_schema这个数据库中保存了MySQL服务器所有数据库的信息,如:数据库名、数据库表、表的数据信息与访问权限等。information_schema的表tables记录了所有数据库的表的信息 information_schema的表columns记录了所有数据库的表字段详细的信息我们代码中可以可以通过Sql语句查询出当前数据库中所有表的信息,这里已 eladmin 为例。# 显示部分数据:表名称、数据库引擎、编码、表备注、创建时间 select table_name ,create_time , engine, table_collation, table_comment from information_schema.tables where table_schema = (select database());知道表的数据后,可以查询出表字段的详细数据,这里用 job 表为例sql语句如下:# 显示部分数据:字段名称、字段类型、字段注释、字段键类型等 select column_name, is_nullable, data_type, column_comment, column_key, extra from information_schema.columns where table_schema = (select database()) and table_name = "job";有了表字段信息的数据后,通过程序将数据库表字段类型转换成Java语言的字段类型,再通过FreeMarker创建模板,将数据写入到模板,输出成文件即可实现代码生成功能。代码实现这里只贴出核心代码,源码可查询文末地址,首先创建一个新的spring boot 项目,选择如下依赖Maven完整依赖如下<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-freemarker</artifactId> </dependency> <!-- 配置管理工具 --> <dependency> <groupId>commons-configuration</groupId> <artifactId>commons-configuration</artifactId> <version>1.9</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies>项目结构如下教程开始修改Spring boot 配置文件 application.yml,如下service: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/eladmin?serverTimezone=Asia/Shanghai username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver jpa: show-sql: true在 resources 目录下创建 Mysql 字段与 Java字段对应关系的配置文件 generator.properties,生成代码时字段转换时使用tinyint=Integer smallint=Integer mediumint=Integer int=Integer integer=Integer bigint=Long float=Float double=Double decimal=BigDecimal bit=Boolean char=String varchar=String tinytext=String text=String mediumtext=String longtext=String date=Timestamp datetime=Timestamp timestamp=Timestamp在 vo 包下创建临时 Vo 类 ColumnInfo,该类的功能用于接收Mysql字段详细信息import lombok.AllArgsConstructor; import lombok.Data; @Data @AllArgsConstructor public class ColumnInfo { /** 数据库字段名称 **/ private Object columnName; /** 允许空值 **/ private Object isNullable; /** 数据库字段类型 **/ private Object columnType; /** 数据库字段注释 **/ private Object columnComment; /** 数据库字段键类型 **/ private Object columnKey; /** 额外的参数 **/ private Object extra; }在 util 包下创建字段工具类 ColumnUtil,该类的功能用于转换mysql类型为Java字段类型,同时添加驼峰转换方法,将表名转换成类名import org.apache.commons.configuration.Configuration; import org.apache.commons.configuration.ConfigurationException; import org.apache.commons.configuration.PropertiesConfiguration; /** * sql字段转java * * @author jie * @date 2019-01-03 */ public class ColumnUtil { private static final char SEPARATOR = '_'; /** * 获取配置信息 */ public static PropertiesConfiguration getConfig() { try { return new PropertiesConfiguration("generator.properties"); } catch (ConfigurationException e) { e.printStackTrace(); } return null; } /** * 转换mysql数据类型为java数据类型 * @param type * @return */ public static String cloToJava(String type){ Configuration config = getConfig(); return config.getString(type,null); } /** * 驼峰命名法工具 * * @return toCamelCase(" hello_world ") == "helloWorld" * toCapitalizeCamelCase("hello_world") == "HelloWorld" * toUnderScoreCase("helloWorld") = "hello_world" */ public static String toCamelCase(String s) { if (s == null) { return null; } s = s.toLowerCase(); StringBuilder sb = new StringBuilder(s.length()); boolean upperCase = false; for (int i = 0; i < s.length(); i++) { char c = s.charAt(i); if (c == SEPARATOR) { upperCase = true; } else if (upperCase) { sb.append(Character.toUpperCase(c)); upperCase = false; } else { sb.append(c); } } return sb.toString(); } /** * 驼峰命名法工具 * * @return toCamelCase(" hello_world ") == "helloWorld" * toCapitalizeCamelCase("hello_world") == "HelloWorld" * toUnderScoreCase("helloWorld") = "hello_world" */ public static String toCapitalizeCamelCase(String s) { if (s == null) { return null; } s = toCamelCase(s); return s.substring(0, 1).toUpperCase() + s.substring(1); } }在 util 包下创建代码生成工具类 GeneratorUtil,该类用于将获取到的Mysql字段信息转出Java字段类型,并且获取代码生成的路径,读取 Template,并且输出成文件,代码如下:import freemarker.template.Configuration; import freemarker.template.Template; import freemarker.template.TemplateException; import lombok.extern.slf4j.Slf4j; import org.springframework.util.ObjectUtils; import java.io.*; import java.time.LocalDate; import java.util.*; /** * 代码生成 * * @author jie * @date 2019-01-02 */ @Slf4j public class GeneratorUtil { private static final String TIMESTAMP = "Timestamp"; private static final String BIGDECIMAL = "BigDecimal"; private static final String PK = "PRI"; private static final String EXTRA = "auto_increment"; /** * 生成代码 * @param columnInfos * @param pack * @param author * @param tableName * @throws IOException */ public static void generatorCode(List<ColumnInfo> columnInfos, String pack, String author, String tableName) throws IOException { Map<String, Object> map = new HashMap<>(); map.put("package", pack); map.put("author", author); map.put("date", LocalDate.now().toString()); map.put("tableName", tableName); // 转换为小写开头的的类名, hello_world == helloWorld String className = ColumnUtil.toCapitalizeCamelCase(tableName); // 转换为大写开头的类名, hello_world == HelloWorld String changeClassName = ColumnUtil.toCamelCase(tableName); map.put("className", className); map.put("changeClassName", changeClassName); // 是否包含 Timestamp 类型 map.put("hasTimestamp", false); // 是否包含 BigDecimal 类型 map.put("hasBigDecimal", false); // 是否为自增主键 map.put("auto", false); List<Map<String, Object>> columns = new ArrayList<>(); for (ColumnInfo column : columnInfos) { Map<String, Object> listMap = new HashMap<>(); listMap.put("columnComment", column.getColumnComment()); listMap.put("columnKey", column.getColumnKey()); String colType = ColumnUtil.cloToJava(column.getColumnType().toString()); String changeColumnName = ColumnUtil.toCamelCase(column.getColumnName().toString()); if (PK.equals(column.getColumnKey())) { map.put("pkColumnType", colType); map.put("pkChangeColName", changeColumnName); } if (TIMESTAMP.equals(colType)) { map.put("hasTimestamp", true); } if (BIGDECIMAL.equals(colType)) { map.put("hasBigDecimal", true); } if (EXTRA.equals(column.getExtra())) { map.put("auto", true); } listMap.put("columnType", colType); listMap.put("columnName", column.getColumnName()); listMap.put("isNullable", column.getIsNullable()); listMap.put("changeColumnName", changeColumnName); columns.add(listMap); } map.put("columns", columns); Configuration configuration = new Configuration(Configuration.VERSION_2_3_23); configuration.setClassForTemplateLoading(GeneratorUtil.class, "/template"); Template template = configuration.getTemplate("Entity.ftl"); // 获取文件路径 String filePath = getAdminFilePath(pack, className); File file = new File(filePath); // 生成代码 genFile(file, template, map); } /** * 定义文件路径以及名称 */ private static String getAdminFilePath(String pack, String className) { String ProjectPath = System.getProperty("user.dir") + File.separator; String packagePath = ProjectPath + File.separator + "src" + File.separator + "main" + File.separator + "java" + File.separator; if (!ObjectUtils.isEmpty(pack)) { packagePath += pack.replace(".", File.separator) + File.separator; } return packagePath + "entity" + File.separator + className + ".java"; } private static void genFile(File file, Template template, Map<String, Object> params) throws IOException { File parentFile = file.getParentFile(); // 创建目录 if (null != parentFile && !parentFile.exists()) { parentFile.mkdirs(); } //创建输出流 Writer writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file), "UTF-8")); //输出模板和数据模型都对应的文件 try { template.process(params, writer); } catch (TemplateException e) { e.printStackTrace(); } } }在 resources 的 template 目录下创建 framework 模板 Entity.ftl,代码如下:package ${package}.entity; import lombok.Data; import javax.persistence.*; <#if hasTimestamp> import java.sql.Timestamp; </#if> <#if hasBigDecimal> import java.math.BigDecimal; </#if> import java.io.Serializable; /** * @author ${author} * @date ${date} */ @Entity @Data @Table(name="${tableName}") public class ${className} implements Serializable { <#if columns??> <#list columns as column> <#if column.columnComment != ''> // ${column.columnComment} </#if> <#if column.columnKey = 'PRI'> @Id <#if auto> @GeneratedValue(strategy = GenerationType.IDENTITY) </#if> </#if> @Column(name = "${column.columnName}"<#if column.columnKey = 'UNI'>,unique = true</#if><#if column.isNullable = 'NO' && column.columnKey != 'PRI'>,nullable = false</#if>) private ${column.columnType} ${column.changeColumnName}; </#list> </#if> }创建服务类 GeneratorService,该类用于获取数据库表的源数据import org.springframework.stereotype.Service; import org.springframework.util.ObjectUtils; import javax.persistence.EntityManager; import javax.persistence.PersistenceContext; import javax.persistence.Query; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * 代码生成服务 */ @Service public class GeneratorService { @PersistenceContext private EntityManager em; public List<ColumnInfo> getColumns(String tableName) { StringBuilder sql = new StringBuilder("select column_name, is_nullable, data_type, column_comment, column_key, extra from information_schema.columns where "); if(!ObjectUtils.isEmpty(tableName)){ sql.append("table_name = '").append(tableName).append("' "); } sql.append("and table_schema = (select database()) order by ordinal_position"); Query query = em.createNativeQuery(sql.toString()); List result = query.getResultList(); List<ColumnInfo> columnInfos = new ArrayList<>(); for (Object o : result) { Object[] obj = (Object[])o; columnInfos.add(new ColumnInfo(obj[0],obj[1],obj[2],obj[3],obj[4],obj[5])); } return columnInfos; } }由于没有前端页面,所以只能在测试类中演示代码生成功能,GeneratorDomeApplicationTests 修改如下import com.ydyno.util.GeneratorUtil; import com.ydyno.vo.ColumnInfo; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException; import java.util.List; @SpringBootTest class GeneratorDomeApplicationTests { @Autowired private GeneratorService generatorService; @Test void genTest() throws IOException { String tableName = "job"; String pack = "com.ydyno"; String author = "Zheng Jie"; List<ColumnInfo> columnInfos = generatorService.getColumns(tableName); GeneratorUtil.generatorCode(columnInfos,pack,author,tableName); } }执行后,查看创建好的Entity
-
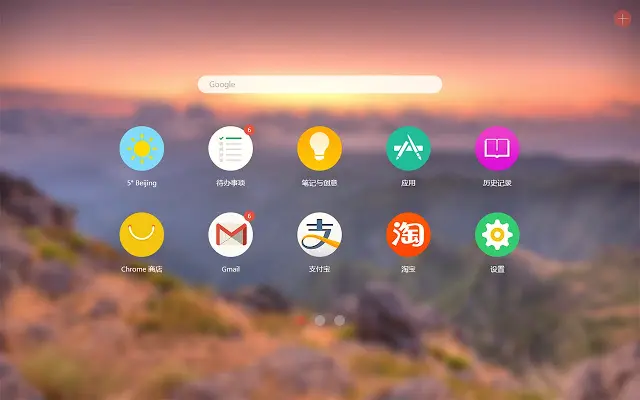
谷歌插件分享 - 绝美的新标签页(Infinity)插件 百万用户选择的新标签页,自由添加网站图标,云端高清壁纸,快速访问书签、天气、笔记、待办事项、扩展管理与历史记录。插件功能精美的图标(logo):扁平化设计风格,国内外200多个热门常用图标。高清壁纸:从3万5千张超清壁纸中,一张一张搭配图标,精心挑选出365张,形成每日一图;当然你也可以从你自己电脑上选择图片作为壁纸。云同步:时间备份数据到云端,一键从云端恢复。智能邮件通知:Gmail邮件自动提醒功能。待办事项:随时查看你要做的事和你做过的事。个性化搜索:你可以选择你想使用的搜索引擎,你还可以定制个人的附加搜索引擎。App扩展管理:随时随地快捷方便的管理你的扩展。历史记录管理:查看搜索你的记录。笔记:记录生活点滴。插件下载隐藏内容,请前往内页查看详情插件安装下载后,最好保存到一个单独的文件夹,避免误删除,打开你的Chrome浏览器:直接在网址输入: chrome://extensions/打开开发者模式,将插件【crx格式】拖入浏览器安装即可Infinity 预览 图一 图二
-
持续集成工具 Jenkins 介绍与安装 我们在项目开发过程中,需要将已开发完的功能提交到 Git 上,然后构建与发布。如果更新很频繁,这将变得非常繁琐,并且会浪费大量时间。使用Jenkins就可以解决这个问题,当代码提交时就可以通过Jenkins自动构建与发布项目。什么是持续集成持续集成就是每完成一部分功能就向下个环节交付,通过快速的版本迭代,尽早的发现存在的问题以便开发人员修复。一个完整的持续集成系统应包含如下内容:1、一个自动构建过程(自动编译、分发、部署和测试等)2、一个代码存储库(版本控制与维护)3、一个持续集成服务器(Jenkins)什么是JenkinsJenkins是一个开源的持续集成(CI)工具,主要用于持续、自动的构建/测试软件项目。Jenkins用Java语言编写,使用时必须配置JDk环境。Jenkins 通常与版本管理工具(Git、Svn)和构建工具(Maven、Gradle)结合使用。Jenkins拥有丰富的插件库,使用Jenkins可以帮助我们自动构建各类项目Jenkins 安装安装JDK环境# 检索1.8的列表 yum list java-1.8* # 安装JDK yum install java-1.8.0-openjdk* -y # 测试 java -version安装Jenkins# 新建文件夹并且定位到改目录 mkdir /usr/local/jenkins && cd /usr/local/jenkins # 下载安装包 wget http://mirrors.jenkins-ci.org/war/latest/jenkins.war # 安装Screen,以便后台运行 yum install screen # 启动应用 nohup java -jar /usr/local/jenkins/jenkins.war --httpPort=8000 &进入系统启动应用后,在浏览器输入:ip:端口Jenkins 第一次启动时会在控制台打印出密码或者使用提示中的路径获取密码cat /root/.jenkins/secrets/initialAdminPassword进入系统后,设置用户名与密码即可
-
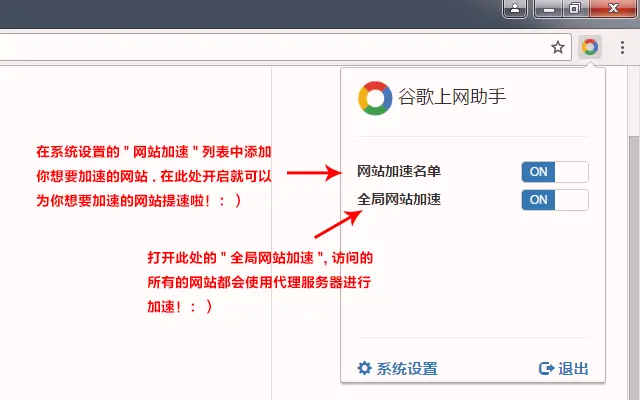
谷歌插件分享 - 外贸/开发人员必备插件【谷歌上网助手】 专门为科研、外贸、跨境电商、海淘人员、开发人员服务的科学上网插件,chrome内核浏览器专用!使用《谷歌上网助手》,无需其他配置,即可访问谷歌搜索、谷歌邮箱、谷歌商店等外网资源插件下载隐藏内容,请前往内页查看详情安装方式下载后,最好保存到一个单独的文件夹,避免误删除,打开你的Chrome浏览器直接在网址输入: chrome://extensions/打开开发者模式,将插件【crx格式】拖入浏览器安装即可安装完成后注册一个新账号,登陆后就能愉快的科学上网了插件预览注意PS:新注册的用户有三天体验会员,会员过期后也能使用,可能速度会慢些 ~
-
GIT 常用命令整理 master : 默认开发分支; origin : 默认远程版本库初始化操作$ git config -global user.name <name> #设置提交者名字 $ git config -global user.email <email> #设置提交者邮箱 $ git config -global core.editor <editor> #设置默认文本编辑器 $ git config -global merge.tool <tool> #设置解决合并冲突时差异分析工具 $ git config -list #检查已有的配置信息创建新版本库$ git clone <url> #克隆远程版本库 $ git init #初始化本地版本库修改和提交$ git add . #添加所有改动过的文件 $ git add <file> #添加指定的文件 $ git mv <old> <new> #文件重命名 $ git rm <file> #删除文件 $ git rm -cached <file> #停止跟踪文件但不删除 $ git commit -m <file> #提交指定文件 $ git commit -m “commit message” #提交所有更新过的文件 $ git commit -amend #修改最后一次提交 $ git commit -C HEAD -a -amend #增补提交(不会产生新的提交历史纪录)查看提交历史$ git log #查看提交历史 $ git log -p <file> #查看指定文件的提交历史 $ git blame <file> #以列表方式查看指定文件的提交历史 $ gitk #查看当前分支历史纪录 $ gitk <branch> #查看某分支历史纪录 $ gitk --all #查看所有分支历史纪录 $ git branch -v #每个分支最后的提交 $ git status #查看当前状态 $ git diff #查看变更内容撤消操作$ git reset -hard HEAD #撤消工作目录中所有未提交文件的修改内容 $ git checkout HEAD <file1> <file2> #撤消指定的未提交文件的 修改内容 $ git checkout HEAD. #撤消所有文件 $ git revert <commit> #撤消指定的提交分支与标签$ git branch #显示所有本地分支 $ git checkout <branch/tagname> #切换到指定分支或标签 $ git branch <new-branch> #创建新分支 $ git branch -d <branch> #删除本地分支 $ git tag #列出所有本地标签 $ git tag <tagname> #基于最新提交创建标签 $ git tag -d <tagname> #删除标签合并与衍合$ git merge <branch> #合并指定分支到当前分支 $ git rebase <branch> #衍合指定分支到当前分支远程操作$ git remote -v #查看远程版本库信息 $ git remote show <remote> #查看指定远程版本库信息 $ git remote add <remote> <url> #添加远程版本库 $ git fetch <remote> #从远程库获取代码 $ git pull <remote> <branch> #下载代码及快速合并 $ git push <remote> <branch> #上传代码及快速合并 $ git push <remote> : <branch>/<tagname> #删除### 远程分支或标签 $ git push -tags #上传所有标签