-
大佬,互换个友链, 已添加您了
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
-
博主已经添加了名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
-
古德古德
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
} 名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
知了小站
不怕学问浅,就怕志气短。
搜索到
17
篇与
的结果
-
 Java 模拟死锁以及如何避免死锁 模拟死锁死锁是多线程编程中常见的问题,它发生在两个或多个线程相互等待对方释放资源的情况下。以下是一个简单的Java死锁模拟示例:public class DeadlockExample { public static void main(String[] args) { // 创建两个共享资源 final Object resource1 = new Object(); final Object resource2 = new Object(); // 线程1尝试获取资源1,然后资源2 Thread thread1 = new Thread(() -> { synchronized (resource1) { System.out.println("Thread 1: Locked resource 1"); try { // 为了增加死锁的可能性,线程1休眠一段时间 Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resource2) { System.out.println("Thread 1: Locked resource 2"); } } }); // 线程2尝试获取资源2,然后资源1 Thread thread2 = new Thread(() -> { synchronized (resource2) { System.out.println("Thread 2: Locked resource 2"); try { // 为了增加死锁的可能性,线程2休眠一段时间 Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resource1) { System.out.println("Thread 2: Locked resource 1"); } } }); // 启动线程1和线程2 thread1.start(); thread2.start(); } }在这个例子中,两个线程分别尝试获取两个共享资源,但它们的获取顺序相反。如果这两个线程在不同的时刻开始执行,可能不会发生死锁,但如果它们同时开始执行,就有可能因为资源争夺而导致死锁。如何避免死锁避免死锁是多线程编程中非常重要的一个方面,以下是一些常见的避免死锁的策略:锁的顺序:定义一个全局的锁获取顺序,然后在所有线程中都按照相同的顺序获取锁。这样可以避免不同线程以不同的顺序获取锁而导致死锁。锁的超时机制:在获取锁的时候,设置一个超时机制。如果某个线程在一定时间内无法获取到所需的锁,就释放已经获取的锁,并重新尝试获取锁,或者执行其他逻辑来避免死锁。使用 tryLock() 方法:在Java中,Lock 接口提供了 tryLock() 方法,它可以尝试获取锁,但不会一直等待。通过使用这个方法,你可以在获取锁失败时执行一些逻辑,而不是一直等待锁。锁的粒度:设计时考虑锁的粒度。如果锁的范围太大,竞争会增加,容易导致死锁。将锁的范围缩小到最小必要范围,可以减少死锁的概率。使用事务:在数据库操作中,使用事务可以避免某些类型的死锁。数据库事务通常会自动处理资源的锁定和释放。死锁检测和处理:一些系统提供死锁检测机制,可以检测到死锁的发生,并采取一些措施,例如自动释放锁或终止某些线程。避免循环等待:设定一个全局的资源获取顺序,并要求所有线程按照相同的顺序获取资源,以避免循环等待的情况。使用高级同步工具:Java提供了一些高级的同步工具,如 java.util.concurrent 包中的 ReentrantLock、Semaphore 等,它们提供更灵活的控制和避免死锁的机制。避免死锁是一个复杂的问题,需要在设计和实现阶段考虑。以上策略可以根据具体情况进行选择和组合,以提高多线程程序的稳定性。
Java 模拟死锁以及如何避免死锁 模拟死锁死锁是多线程编程中常见的问题,它发生在两个或多个线程相互等待对方释放资源的情况下。以下是一个简单的Java死锁模拟示例:public class DeadlockExample { public static void main(String[] args) { // 创建两个共享资源 final Object resource1 = new Object(); final Object resource2 = new Object(); // 线程1尝试获取资源1,然后资源2 Thread thread1 = new Thread(() -> { synchronized (resource1) { System.out.println("Thread 1: Locked resource 1"); try { // 为了增加死锁的可能性,线程1休眠一段时间 Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resource2) { System.out.println("Thread 1: Locked resource 2"); } } }); // 线程2尝试获取资源2,然后资源1 Thread thread2 = new Thread(() -> { synchronized (resource2) { System.out.println("Thread 2: Locked resource 2"); try { // 为了增加死锁的可能性,线程2休眠一段时间 Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resource1) { System.out.println("Thread 2: Locked resource 1"); } } }); // 启动线程1和线程2 thread1.start(); thread2.start(); } }在这个例子中,两个线程分别尝试获取两个共享资源,但它们的获取顺序相反。如果这两个线程在不同的时刻开始执行,可能不会发生死锁,但如果它们同时开始执行,就有可能因为资源争夺而导致死锁。如何避免死锁避免死锁是多线程编程中非常重要的一个方面,以下是一些常见的避免死锁的策略:锁的顺序:定义一个全局的锁获取顺序,然后在所有线程中都按照相同的顺序获取锁。这样可以避免不同线程以不同的顺序获取锁而导致死锁。锁的超时机制:在获取锁的时候,设置一个超时机制。如果某个线程在一定时间内无法获取到所需的锁,就释放已经获取的锁,并重新尝试获取锁,或者执行其他逻辑来避免死锁。使用 tryLock() 方法:在Java中,Lock 接口提供了 tryLock() 方法,它可以尝试获取锁,但不会一直等待。通过使用这个方法,你可以在获取锁失败时执行一些逻辑,而不是一直等待锁。锁的粒度:设计时考虑锁的粒度。如果锁的范围太大,竞争会增加,容易导致死锁。将锁的范围缩小到最小必要范围,可以减少死锁的概率。使用事务:在数据库操作中,使用事务可以避免某些类型的死锁。数据库事务通常会自动处理资源的锁定和释放。死锁检测和处理:一些系统提供死锁检测机制,可以检测到死锁的发生,并采取一些措施,例如自动释放锁或终止某些线程。避免循环等待:设定一个全局的资源获取顺序,并要求所有线程按照相同的顺序获取资源,以避免循环等待的情况。使用高级同步工具:Java提供了一些高级的同步工具,如 java.util.concurrent 包中的 ReentrantLock、Semaphore 等,它们提供更灵活的控制和避免死锁的机制。避免死锁是一个复杂的问题,需要在设计和实现阶段考虑。以上策略可以根据具体情况进行选择和组合,以提高多线程程序的稳定性。 -
Jpa 持久层中使用自定义对象接收数据 在 JPA 持久层中,可以自定义接收数据的对象。这通常用于查询操作,其中查询结果不完全匹配现有的实体类,或者需要仅返回某些字段的结果。以下示例,展示如何在 JPA 持久层中自定义接收数据的对象假设有一个名为 Person 的实体类,包含 id、name 和 age 字段:@Entity @Table(name = "person") public class Person { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; private int age; // 省略构造函数、getter 和 setter 方法 }现在我们只想查询人员的姓名和年龄,并将结果封装到自定义的数据对象 PersonInfo 中:public class PersonInfo { private String name; private int age; // 省略构造函数、getter 和 setter 方法 }第一种方式@Repository public class PersonRepository { @PersistenceContext private EntityManager entityManager; public List<PersonInfo> getPersonInfo() { String query = "SELECT new com.example.PersonInfo(p.name, p.age) FROM Person p"; TypedQuery<PersonInfo> typedQuery = entityManager.createQuery(query, PersonInfo.class); return typedQuery.getResultList(); } }在上面的代码中,我们使用 SELECT new 关键字创建了一个 PersonInfo 对象,并将查询结果映射到该对象。通过使用构造函数,可以选择性地指定要接收的字段。第二种方式使用 Spring Data JPA 的 Repository 接口@Repository public interface PersonRepository extends JpaRepository<Person, Long> { @Query("SELECT new com.example.PersonInfo(p.name, p.age) FROM Person p") List<PersonInfo> getPersonInfo(); }在上面的示例中,我们使用了 @Query 注解,并指定了一个自定义的查询语句。在查询语句中,我们使用了 new 关键字创建了一个 PersonInfo 对象,并将查询结果映射到该对象。注意点在查询语句中,com.example.PersonInfo 是 PersonInfo 类的完全限定名,确保使用正确的包名,确保创建了对应的构造方法。
-
Java 开发之 BigDecimal 用法细节详解 一、BigDecimal 概述 Java 在 java.math 包中提供的 API 类 BigDecimal,用来对超过 16 位有效位的数进行精确的运算。双精度浮点型变量 double 可以处理 16 位有效数,但在实际应用中,可能需要对更大或者更小的数进行运算和处理。一般情况下,对于那些不需要准确计算精度的数字,我们可以直接使用 Float 和 Double 处理,但是 Double.valueOf(String) 和 Float.valueOf(String) 会丢失精度。所以开发中,如果我们需要精确计算的结果,则必须使用 BigDecimal 类来操作。BigDecimal所创建的是对象,故我们不能使用传统的 +、-、*、/ 等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法。方法中的参数也必须是 BigDecimal 的对象。构造器是类的特殊方法,专门用来创建对象,特别是带有参数的对象。二、BigDecimal 常用构造函数2.1、常用构造函数// 创建一个具有参数所指定整数值的对象 BigDecimal(int) // 创建一个具有参数所指定双精度值的对象 BigDecimal(double) // 创建一个具有参数所指定长整数值的对象 BigDecimal(long) // 创建一个具有参数所指定以字符串表示的数值的对象 BigDecimal(String)2.2、使用问题分析使用示例:BigDecimal a =new BigDecimal(0.1); System.out.println("a values is:"+a); System.out.println("====================="); BigDecimal b =new BigDecimal("0.1"); System.out.println("b values is:"+b);结果示例:a values is:0.1000000000000000055511151231257827021181583404541015625 ===================== b values is:0.1原因分析:1)参数类型为 double 的构造方法的结果有一定的不可预知性。有人可能认为在 Java 中写入 newBigDecimal(0.1) 所创建的 BigDecimal 正好等于 0.1(非标度值 1,其标度为 1),但是它实际上等于 0.1000000000000000055511151231257827021181583404541015625。这是因为 0.1 无法准确地表示为 double(或者说对于该情况,不能表示为任何有限长度的二进制小数)。这样,传入到构造方法的值不会正好等于 0.1(虽然表面上等于该值)。2)String 构造方法是完全可预知的:写入 newBigDecimal(“0.1”) 将创建一个 BigDecimal,它正好等于预期的 0.1。因此,比较而言, 通常建议优先使用String构造方法。3)当 double 必须用作 BigDecimal 的源时,请注意,此构造方法提供了一个准确转换;它不提供与以下操作相同的结果:先使用 Double.toString(double) 方法,然后使用 BigDecimal(String) 构造方法,将 double 转换为 String。要获取该结果,请使用 static valueOf(double) 方法。三、BigDecimal 常用方法详解3.1、常用方法// BigDecimal 对象中的值相加,返回 BigDecimal 对象 add(BigDecimal) // BigDecimal 对象中的值相减,返回 BigDecimal 对象 subtract(BigDecimal) // BigDecimal 对象中的值相乘,返回 BigDecimal 对象 multiply(BigDecimal) // BigDecimal 对象中的值相除,返回 BigDecimal 对象 divide(BigDecimal) // 将 BigDecimal 对象中的值转换成字符串 toString() // 将 BigDecimal 对象中的值转换成双精度数 doubleValue() // 将 BigDecimal 对象中的值转换成单精度数 floatValue() // 将 BigDecimal 对象中的值转换成长整数 longValue() // 将 BigDecimal 对象中的值转换成整数 intValue()3.2、BigDecimal大小比较java 中对 BigDecimal 比较大小一般用的是 bigdemical 的 compareTo 方法int a = bigdemical.compareTo(bigdemical2)返回结果分析:a = -1,表示bigdemical小于bigdemical2; a = 0,表示bigdemical等于bigdemical2; a = 1,表示bigdemical大于bigdemical2;举例:a大于等于bnew bigdemica(a).compareTo(new bigdemical(b)) >= 0四、BigDecimal 格式化由于 NumberFormat 类的 format() 方法可以使用 BigDecimal 对象作为其参数,可以利用 BigDecimal 对超出 16 位有效数字的货币值,百分值,以及一般数值进行格式化控制。以利用 BigDecimal 对货币和百分比格式化为例。首先,创建 BigDecimal 对象,进行 BigDecimal 的算术运算后,分别建立对货币和百分比格式化的引用,最后利用 BigDecimal 对象作为 format() 方法的参数,输出其格式化的货币值和百分比。NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用 NumberFormat percent = NumberFormat.getPercentInstance(); //建立百分比格式化引用 percent.setMaximumFractionDigits(3); //百分比小数点最多3位 BigDecimal loanAmount = new BigDecimal("15000.48"); //贷款金额 BigDecimal interestRate = new BigDecimal("0.008"); //利率 BigDecimal interest = loanAmount.multiply(interestRate); //相乘 System.out.println("贷款金额:\t" + currency.format(loanAmount)); System.out.println("利率:\t" + percent.format(interestRate)); System.out.println("利息:\t" + currency.format(interest)); 结果:贷款金额: ¥15,000.48 利率: 0.8% 利息: ¥120.00BigDecimal 格式化保留两位小数,不足则补 0:public class NumberFormat { public static void main(String[] s){ System.out.println(formatToNumber(new BigDecimal("3.435"))); System.out.println(formatToNumber(new BigDecimal(0))); System.out.println(formatToNumber(new BigDecimal("0.00"))); System.out.println(formatToNumber(new BigDecimal("0.001"))); System.out.println(formatToNumber(new BigDecimal("0.006"))); System.out.println(formatToNumber(new BigDecimal("0.206"))); } /** * @desc 1.0~1之间的BigDecimal小数,格式化后失去前面的0,则前面直接加上0。 * 2.传入的参数等于0,则直接返回字符串"0.00" * 3.大于1的小数,直接格式化返回字符串 * @param obj传入的小数 * @return */ public static String formatToNumber(BigDecimal obj) { DecimalFormat df = new DecimalFormat("#.00"); if(obj.compareTo(BigDecimal.ZERO)==0) { return "0.00"; }else if(obj.compareTo(BigDecimal.ZERO)>0&&obj.compareTo(new BigDecimal(1))<0){ return "0"+df.format(obj).toString(); }else { return df.format(obj).toString(); } } }结果为:3.44 0.00 0.00 0.00 0.01 0.21五、BigDecimal常见异常5.1、除法的时候出现异常java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result原因分析:通过BigDecimal的divide方法进行除法时当不整除,出现无限循环小数时,就会抛异常:java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.解决方法:divide 方法设置精确的小数点,如:divide(xxxxx,2)六、BigDecimal总结6.1、总结在需要精确的小数计算时再使用 BigDecimal,BigDecimal 的性能比 double 和 float 差,在处理庞大,复杂的运算时尤为明显。故一般精度的计算没必要使用 BigDecimal。尽量使用参数类型为 String 的构造函数。BigDecimal 都是不可变的(immutable)的, 在进行每一次四则运算时,都会产生一个新的对象 ,所以在做加减乘除运算时要记得要保存操作后的值。6.2、工具类推荐package com.vivo.ars.util; import java.math.BigDecimal; /** * 用于高精确处理常用的数学运算 */ public class ArithmeticUtils { //默认除法运算精度 private static final int DEF_DIV_SCALE = 10; /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static double add(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.add(b2).doubleValue(); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static BigDecimal add(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @param scale 保留scale 位小数 * @return 两个参数的和 */ public static String add(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static double sub(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.subtract(b2).doubleValue(); } /** * 提供精确的减法运算。 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static BigDecimal sub(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @param scale 保留scale 位小数 * @return 两个参数的差 */ public static String sub(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static double mul(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.multiply(b2).doubleValue(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static BigDecimal mul(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static double mul(double v1, double v2, int scale) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return round(b1.multiply(b2).doubleValue(), scale); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static String mul(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到 * 小数点以后10位,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @return 两个参数的商 */ public static double div(double v1, double v2) { return div(v1, v2, DEF_DIV_SCALE); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示表示需要精确到小数点以后几位。 * @return 两个参数的商 */ public static double div(double v1, double v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示需要精确到小数点以后几位 * @return 两个参数的商 */ public static String div(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v1); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static double round(double v, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(Double.toString(v)); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static String round(String v, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(v); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static String remainder(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.remainder(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 BigDecimal * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static BigDecimal remainder(BigDecimal v1, BigDecimal v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } return v1.remainder(v2).setScale(scale, BigDecimal.ROUND_HALF_UP); } /** * 比较大小 * * @param v1 被比较数 * @param v2 比较数 * @return 如果v1 大于v2 则 返回true 否则false */ public static boolean compare(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); int bj = b1.compareTo(b2); boolean res; if (bj > 0) res = true; else res = false; return res; } }原文地址:https://www.cnblogs.com/zhangyinhua/p/11545305.html
-
Spring boot 使用 logback 自定义日志脱敏教程 前言在我们书写代码的时候,会书写许多日志代码,但是有些敏感数据是需要进行安全脱敏处理的。对于日志脱敏的方式有很多,常见的有① 使用 conversionRule 标签,继承 MessageConverter② 书写一个脱敏工具类,在打印日志的时候对特定特字段进行脱敏返回两种方式各有优缺点:第一种方式需要修改代码,不符合开闭原则。第二种方式,需要在日志方法的参数进行脱敏,对原生日志有入侵行为。自定义脱敏组件(slf4j + logback)一个项目在书写了很多打印日志的代码,但是后面有了脱敏需求,如果我们去手动改动代码,会花费大量时间。如果引入本组件,完成配置即可轻松完成脱敏。(仅需三步可轻松配置)一、自定义脱敏组件 - 脱敏效果演示二、自定义脱敏组件 - 使用方式1、引入Jar包依赖前提是你将Jar包打入本地仓库,Jar包地址见后文。<dependency> <groupId>pers.liuchengyin</groupId> <artifactId>logback-desensitization</artifactId> <version>1.0.0</version> </dependency>2、替换日志文件配置类(logback.xml)日志打印方式都只需要替换成脱敏的类即可,如果你的业务不需要,则无需替换。① ConsoleAppender - 控制台脱敏// 原类 ch.qos.logback.core.ConsoleAppender // 替换类 pers.liuchengyin.logbackadvice.LcyConsoleAppender② RollingFileAppender - 滚动文件// 原类 ch.qos.logback.core.rolling.RollingFileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyRollingFileAppender③ FileAppender - 文件// 原类 ch.qos.logback.core.FileAppender // 替换类 pers.liuchengyin.logbackadvice.LcyFileAppender替换示例:<property name="CONSOLE_LOG_PATTERN" value="%yellow(%date{yyyy-MM-dd HH:mm:ss}) |%highlight(%-5level) |%blue(%thread) |%blue(%file:%line) |%green(%logger) |%cyan(%msg%n)"/> <!-- ConsoleAppender 控制台输出日志 --> <appender name="CONSOLE" class="pers.liuchengyin.logbackadvice.LcyConsoleAppender"> <encoder> <pattern> ${CONSOLE_LOG_PATTERN} </pattern> </encoder> </appender>3、添加脱敏配置文件(logback-desensitize.yml)该配置文件应该放在 resources 文件下三、自定义脱敏组件 - 脱敏规范1、支持数据类型八大基本类型及其包装类型、Map、List、业务里的Pojo对象、List<业务里的Pojo对象>、JSON字符串。注:在配置文件中配置的时候,只需要配置对象里的属性值就行。2、不支持的数据类型List<八大基本类型及包装类型>,因为不知道脱敏的数据源具体是哪一个。3、匹配规则key + 分割符 + value,目前仅支持冒号 (:) 和等号 (=),示例如下:log.info("your email:{}, your phone:{}", "123456789@qq.com","15310763497"); log.info("your email={}, your cellphone={}", "123456789@qq.com","15310763497");key:定义了对应需要脱敏的关键字,如上诉的 email、phone 等以及业务对象中的字段、Map 中的 Key、JSON 中的 Keyvalue:需要脱敏的值,如上诉的 123456789@qq.com、153107634974、日志规范建议书写日志的时候尽量规范,对于key为中文的是没有办法脱敏的,规范程度可以见脱敏效果演示里的代码。四、logback-desensitize.yml配置说明# 日志脱敏 log-desensitize: # 是否忽略大小写匹配,默认为true ignore: true # 是否开启脱敏,默认为false open: true # pattern下的key/value为固定脱敏规则 pattern: # 邮箱 - @前第4-7位脱敏 email: "@>(4,7)" # qq邮箱 - @后1-3位脱敏 qqemail: "@<(1,3)" # 姓名 - 姓脱敏,如*杰伦 name: 1,1 # 密码 - 所有需要完全脱敏的都可以使用内置的password password: password patterns: # 身份证号,key后面的字段都可以匹配以下规则(用逗号分隔) - key: identity,idcard # 定义规则的标识 custom: # defaultRegex表示使用组件内置的规则:identity表示身份证号 - 内置的18/15位 - defaultRegex: identity position: 9,13 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 9,10 # 电话号码,key后面的字段都可以匹配以下规则(用逗号分隔) - key: phone,cellphone,mobile custom: # 手机号 - 内置的11位手机匹配规则 - defaultRegex: phone position: 4,7 # 自定义正则匹配表达式:座机号(带区号,号码七位|八位) - customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" # -后面的1-4位脱敏 position: "-<(1,4)" # 自定义正则匹配表达式:座机号(不带区号) - customRegex: "^[0-9]{7,8}" position: 3,5 # 内置的other表示如果其他规则都无法匹配到,则按该规则处理 - defaultRegex: other position: 1,3 # 这种方式不太推荐 - 一旦匹配不上,就不会脱敏 - key: localMobile custom: customRegex: "^0[0-9]{2,3}-[0-9]{7,8}" position: 1,3上面这个配置是相对完整的,一定要严格遵守层级配置格式。自定义脱敏支持的方式1、key:value的方式phone:4,7,表示 phone 属性的 4-7 位进行脱敏原始数据:13610357861脱敏后:136**78612、以符号作为起始、结束节点作为脱敏标志email:"@>(4,7)",@ 为脱敏标志,> 表示其为结束节点,< 表示其为开始节点。即 @> 表示对 @ 之前的进行脱敏,@< 表示对 @ 之后的进行脱敏。这个示例就是 @ 前的数据的第 4-7 位进行脱敏。注意:这种规则里的双引号、括号不能省略,其次 : 和 = 不能作为标志符号,因为和匹配规则有冲突。原始数据:123456789@qq.com"@>(4,7)"脱敏后:123**89@qq.com"@<(1,3)"脱敏后:123456789@*com3、自定义正则脱敏patterns: # 手机号 - key: phone,mobile custom: # 手机号的正则 - customRegex: "^1[0-9]{10}" # 脱敏范围 position: 4,7customRegex:正则表达式,如果符合该表达式,则使用其对应的脱敏规则 (position)4、一个字段,根据多种值含义进行自定义脱敏比如说,username 字段的值可以是手机号、也可以是邮箱,这个值动态改变的,前面几种方式都没办法解决,可以使用该方式。patterns: - key: username custom: # 手机号 - 11位 - defaultRegex: phone position : 4,7 # 邮箱 - @ - defaultRegex: email position : "@>(3,12)" # 身份证 - 15/18位 - defaultRegex: identity position : 1,3 # 自定义正则 - customRegex: "^1[0-9]{10}" position : 1,3 # 都匹配不到时,按照这种规则来 - defaultRegex: other position : 1,3注意:上面示例中匹配规则里的 双引号和括号 都不能省略该组件内置四种匹配规则:手机号、身份证号、邮箱、other(其他匹配不到时用的),内置一种脱敏方式:password,表示完全脱敏,可用于 pattren 下的。注:当pattern和patterns下的key有重复的时候,只会使用pattern下指定的方式进行脱敏。Jar包地址和源码地址Jar包Github地址 - logback-desensitization-1.0.0.jar Github地址: Logback和slf4j的日志脱敏组件Demo Gitee地址: Logback和slf4j的日志脱敏组件DemoJar包打入Maven本地仓库的方式1、下载Jar包,放在一个文件夹里2、在这个文件夹里打开cmd(打开cmd,进入到这个文件夹)3、执行命令(前提保证maven配置正常,使用mvn -v命令查看是否正常,如果显示版本号表示正常)mvn install:install-file -DgroupId=pers.liuchengyin -DartifactId=logback-desensitization -Dversion=1.0.0 -Dpackaging=jar -Dfile=logback-desensitization-1.0.0.jar命令说明: -DgroupId 表示jar对应的groupId <groupId>pers.liuchengyin</groupId> -DartifactId: 表示jar对应的artifactId <artifactId>logback-desensitization</artifactId> -Dversion 表示jar对应的 version <version>1.0.0</version>原文作者: 九月清晨柳成荫 原文地址:https://blog.csdn.net/qq_40885085/article/details/113385261?spm=1001.2014.3001.5501
-
Jpa进阶,使用 Specification 进行高级查询 前言上一篇文章主要讲了 Jpa 的简单使用,而在实际项目中并不能满足我们的需求。如对多张表的关联查询,以及查询时需要的各种条件,这个时候你可以使用自定义 SQL 语句,但是Jpa并不希望我们这么做,于是就有了一个扩展:使用 Specification 进行查询修改相应代码1、修改 User.class代码用的上一篇文章的,这里在 User 类中进行扩展,待会查询时会用到@Entity @Table(name = "user") public class User { //部分代码略 /** * 加上该注解,在保存该实体时,Jpa将为我们自动设置上创建时间 */ @CreationTimestamp private Timestamp createTime; /** * 加上该注解,在保存或者修改该实体时,Jpa将为我们自动创建时间或更新日期 */ @UpdateTimestamp private Timestamp updateTime; /** * 关联角色,测试多表查询 */ @ManyToOne @JoinColumn(name = "role_id") private Role role; //部分代码略 }2、新增Role.class@Entity @Table(name = "role") public class Role { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(unique = true,nullable = false) private String name; //get set略 }3、修改UserRepository要使用 Specification,需要继承 JpaSpecificationExecutor 接口,修改后的代码如下public interface UserRepo extends JpaRepository<User,Long>, JpaSpecificationExecutor { }4、查看 JpaSpecificationExecutor 源码Specification 是 Spring Data JPA 提供的一个查询规范,这里所有的操作都是围绕 Specification 来进行public interface JpaSpecificationExecutor<T> { Optional<T> findOne(@Nullable Specification<T> var1); List<T> findAll(@Nullable Specification<T> var1); Page<T> findAll(@Nullable Specification<T> var1, Pageable var2); List<T> findAll(@Nullable Specification<T> var1, Sort var2); long count(@Nullable Specification<T> var1); }封装查询Service我这里简单做了下简单封装,编写 UserQueryService.class@Service public class UserQueryService { @Autowired private UserRepo userRepo; /** * 分页加高级查询 */ public Page queryAll(User user, Pageable pageable , String roleName){ return userRepo.findAll(new UserSpec(user,roleName),pageable); } /** * 不分页 */ public List queryAll(User user){ return userRepo.findAll(new UserSpec(user)); } class UserSpec implements Specification<User>{ private User user; private String roleName; public UserSpec(User user){ this.user = user; } public UserSpec(User user,String roleName){ this.user = user; this.roleName = roleName; } @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) { List<Predicate> list = new ArrayList<Predicate>(); /** * 左连接,关联查询 */ Join<Role,User> join = root.join("role",JoinType.LEFT); if(!StringUtils.isEmpty(user.getId())){ /** * 相等 */ list.add(cb.equal(root.get("id").as(Long.class),user.getId())); } if(!StringUtils.isEmpty(user.getUsername())){ /** * 模糊 */ list.add(cb.like(root.get("username").as(String.class),"%"+user.getUsername()+"%")); } if(!StringUtils.isEmpty(roleName)){ /** * 这里的join.get("name"),就是对应的Role.class里面的name */ list.add(cb.like(join.get("name").as(String.class),"%"+roleName+"%")); } if(!StringUtils.isEmpty(user.getCreateTime())){ /** * 大于等于 */ list.add(cb.greaterThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getCreateTime())); } if(!StringUtils.isEmpty(user.getUpdateTime())){ /** * 小于等于 */ list.add(cb.lessThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getUpdateTime())); } Predicate[] p = new Predicate[list.size()]; return cb.and(list.toArray(p)); } } }查询测试1、新增测试数据 @Test public void test3() { /** * 新增角色 */ Role role = new Role(); role.setName("测试角色"); role = roleRepo.save(role); /** * 新增并绑定角色 */ User user = new User("小李",20,"男",role); User user1 = new User("小花",21,"女",role); userRepo.save(user); userRepo.save(user1); }查看数据都已经新增成功了,并且 createTime 和 updateTime 也帮我们加上了2、简单查询 @Test public void Test4(){ /** * 添加查询数据,模糊查询用户名 */ User user = new User(); user.setUsername("花"); List<User> users = userQueryService.queryAll(user); users.forEach(user1 -> { System.out.println(user1.toString()); }); }运行结果如下3、分页+关联查询 @Test public void test5() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> users = userQueryService.queryAll(new User(),pageable,"测试角色"); System.out.println("总数据条数:"+users.getTotalElements()); System.out.println("总页数:"+users.getTotalPages()); System.out.println("当前页数:"+users.getNumber()); users.forEach(user1 -> { System.out.println(user1.toString()); }); } }通过角色的名称查询用户,运行结果如下
-
JPA入门,Spring Boot 整合 JPA 操作数据库 简单了解Jpa(java Persistence API,java持久化 api),它定义了对象关系映射(ORM)以及实体对象持久化的标准接口。在 Spring boot中 JPA 是依靠 Hibernate才得以实现对的,Hibernate 在 3.2 版本中对 JPA 的实现有了完全的支持。Spring Boot 整合 JPA 可使开发者用极简的代码实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!添加依赖#这里添加 Jpa 和 Mysql 的依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>开发Jpa编写实体类定义用户实体类 User//@Entity 表明这个是一个实体类 @Entity //指定表名 @Table(name = "user") public class User { /** * 表明这个字段是主键,并且ID是自增的 */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** * 这样则表示该属性,在数据库中的名称是 username,并且使唯一的且不能为空的 */ @Column(name = "username",unique = true,nullable = false) private String username; private Integer age; private String sex; //get set略 }配置文件说明Spring Boot 配置文件 application.yml 内容如下server: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/jpa username: root password: 123456 jpa: hibernate: #注入方式 ddl-auto: update naming: #Hibernate 命名策略,这里修改下 physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl properties: hibernate: #数据库方言 dialect: org.hibernate.dialect.MySQL5InnoDBDialectddl-auto属性说明常用属性: 自动创建|更新|验证数据库表结构。 **create:** 每次启动时都会删除上一次的生成的表,然后根据你的实体类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。 **create-drop :** 每次加载 hibernate 时根据 model 类生成表,但是 sessionFactory 一关闭,表就自动删除。 **update:** 最常用的属性,第一次加载启动时根据实体类会自动建立起表的结构(前提是先建立好数据库),以后以后再次启动时会根据实体类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。 **validate :** 每次应用启动时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。这里我们使用 update,让应用启动时自动给我们生成 User 表基础操作1、编写 UserRepo 继承 JpaRepositoryimport me.zhengjie.domain.User; import org.springframework.data.jpa.repository.JpaRepository; public interface UserRepo extends JpaRepository<User,Long> { }2、使用默认方法在 test 目录中,新建 UserTests @RunWith(SpringRunner.class) @SpringBootTest public class UserTests { @Autowired private UserRepo userRepo; @Test public void test1() { User user=new User(); //查询全部 List<User> userList = userRepo.findAll(); //根据ID查询 Optional<User> userOptional = userRepo.findById(1L); //保存,成功后会返回成功后的结果 user = userRepo.save(user); //删除 userRepo.delete(user); //根据ID删除 userRepo.deleteById(1L); //计数 Long count = userRepo.count(); //验证是否存在 Boolean b = userRepo.existsById(1l); } } 自定义简单查询自定义的简单查询就是根据方法名来自动生成 SQL,主要的语法是 findXXBy, readAXXBy, queryXXBy, countXXBy, getXXBy 后面跟属性名称:public interface UserRepo extends JpaRepository<User,Long> { /** * 根据 username 查询 * @param username * @return */ User findByUsername(String username); /** * 根据 username 和 age 查询 * @param username * @param age * @return */ User findByUsernameAndAge(String username,Integer age); }具体的关键字,使用方法和生产成 SQL 如下表所示KeywordSampleJPQL snippetAndfindByLastnameAndFirstname… where x.lastname = ?1 and x.firstname = ?2OrfindByLastnameOrFirstname… where x.lastname = ?1 or x.firstname = ?2Is,EqualsfindByFirstnameIs,findByFirstnameEquals… where x.firstname = ?1BetweenfindByStartDateBetween… where x.startDate between ?1 and ?2LessThanfindByAgeLessThan… where x.age < ?1LessThanEqualfindByAgeLessThanEqual… where x.age ⇐ ?1GreaterThanfindByAgeGreaterThan… where x.age > ?1GreaterThanEqualfindByAgeGreaterThanEqual… where x.age >= ?1AfterfindByStartDateAfter… where x.startDate > ?1BeforefindByStartDateBefore… where x.startDate < ?1IsNullfindByAgeIsNull… where x.age is nullIsNotNull,NotNullfindByAge(Is)NotNull… where x.age not nullLikefindByFirstnameLike… where x.firstname like ?1NotLikefindByFirstnameNotLike… where x.firstname not like ?1StartingWithfindByFirstnameStartingWith… where x.firstname like ?1 (parameter bound with appended %)EndingWithfindByFirstnameEndingWith… where x.firstname like ?1 (parameter bound with prepended %)ContainingfindByFirstnameContaining… where x.firstname like ?1 (parameter bound wrapped in %)OrderByfindByAgeOrderByLastnameDesc… where x.age = ?1 order by x.lastname descNotfindByLastnameNot… where x.lastname <> ?1InfindByAgeIn(Collection ages)… where x.age in ?1NotInfindByAgeNotIn(Collection age)… where x.age not in ?1TRUEfindByActiveTrue()… where x.active = trueFALSEfindByActiveFalse()… where x.active = falseIgnoreCasefindByFirstnameIgnoreCase… where UPPER(x.firstame) = UPPER(?1)分页查询Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable);Pageable 是 spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则@Test public void test2() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> list = userRepo.findAll(pageable); }限制查询有时候我们只需要查询前N个元素 /** * 限制查询 */ List<User> queryFirstByAge(Integer age); List<User> queryFirst10ByAge(Integer age);自定义SQL如果项目中由于某些原因 Jpa 自带的已经满足不了我们的需求了,这个时候我们就可以自定义的 SQL 来查询,只需要在 SQL 的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上 @Modifying /** * 自定义SQL,nativeQuery = true,表明使用原生sql */ @Modifying @Query(value = "update User u set u.userName = ?1 where u.id = ?2",nativeQuery = true) void modifyUsernameById(String userName, Long id); @Modifying @Query(value = "delete from User where id = ?1",nativeQuery = true) void deleteByUserId(Long id); @Query(value = "select u from User u where u.id = ?1",nativeQuery = true) User findByUserId(Long id);本文主要讲解了 Jpa 的一些简单的操作,下篇文章将讲解 Jpa 如何使用 Specification 实现复杂的查询,如多表查询,模糊查询,日期的查询等
-
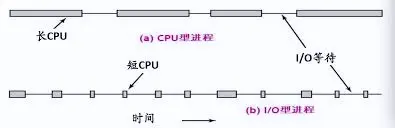
Java开发,配置线程池时线程数应该怎么设置 合理的设置线程数能有效提高 CPU 的利用率,设置线程数又得区分任务是CPU密集型还是 IO密集型。解释CPU密集型 就是需要大量进行计算任务的线程,如:计算1+2+3+...、计算圆周率、视频解码等,这种任务本身不太需要访问I/O设备,CPU的使用率高;IO密集型 就是任务运行时大部分的时间都是CPU在等I/O (硬盘/内存) 的读/写操作,如:查询数据库、文件传输、网络请求等,CPU的使用率不高。根据经验1、CPU密集型:线程数少一点,推荐:CPU内核数 + 1 2、IO密集型:线程数多一些,推荐:CPU内核数 * 2 3、混合型:可以将CPU密集和IO密集的操作分成两个线程池去执行即可!PS:这种方式可能会被面试官找茬根据计算公式根据《Java并发编程实战》书中的计算线程数的公式Ncpu = CPU的数量 Ucpu = 目标CPU的使用率, 0 <= Ucpu <= 1 W/C = 等待时间与计算时间的比率 为保持处理器达到期望的使用率,最优的池的大小等于: Nthreads = Ncpu x Ucpu x (1 + W/C)实战假如在一个请求中,计算操作需要10ms,DB操作需要100ms,对于一台2个CPU的服务器,设置多少合适假设我们需要CPU的使用率达到100%,那么套入公式:`2 x 1 x (1 + 100/10) = 22`但是实际开发中,可能有各种因素的影响,因此就需要我们在这个结果的基础上进行压力测试,最终得到一个完美的线程数量最后补个网图,解释了CPU密集型、IO密集型
-
Jenkins 远程执行 java -jar 脚本不生效,不退出的坑 今天用 Jenkins 自动远程部署 eladmin 遇到了两个坑,这里分享下具体问题以及对应的解决办法。第一个问题问题复现是 jenkins 远程执行 java -jar 的时候报错:nohup: failed to run command 'java': No such file or directoryjava 程序也不能成功运行解决办法在执行脚本前先执行 source /etc/profile 刷新环境变量。source /etc/profile && nohup java -jar **.jar > nohup.out 2>&1 &参考:https://blog.csdn.net/u013189824/article/details/85338221第二个问题问题复现解决完第一个问题后,出现 jenkins 部署不会自动停止的问题,只能等 jenkins 超时退出。虽然远程服务器 java 进程成功启动了,但是 jenkins 都是不稳定的构建。ERROR: Exception when publishing, exception message [Exec timed out or was interrupted after 120,000 ms] Build step 'Send build artifacts over SSH' changed build result to UNSTABLE Finished: UNSTABLE解决办法通过从网上整合资料,终于是找到了解决办法,解决办法可以参考我的配置source /etc/profile cd /home/eladmin BUILD_ID=DONTKILLME nohup bash /home/eladmin/start.sh点击高级,勾选 pty参考: https://blog.51cto.com/u_15316348/3217477 、 https://blog.csdn.net/sinat_29821865/article/details/119906879 再次构建,完美解决
-
Objects.equals(a,b) 、 a.equals(b) 、== 判断对象相等的区别 一、值是null的情况1、a.equals(b), a 是 null, 抛出 NullPointException 异常。2、a.equals(b), a不是 null, b是null, 返回 false3、Objects.equals(a, b) 比较时, 若 a 和 b 都是 null, 则返回 true, 如果 a 和 b 其中一个是 null, 另一个不是 null, 则返回 false。注意:不会抛出空指针异常。null.equals("abc") → 抛出 NullPointerException 异常 "abc".equals(null) → 返回 false null.equals(null) → 抛出 NullPointerException 异常Objects.equals(null, "abc") → 返回 false Objects.equals("abc",null) → 返回 false Objects.equals(null, null) → 返回 true二、值是空字符串的情况1、a 和 b 如果都是空值字符串:"", 则 a.equals(b), 返回的值是 true, 如果 a 和 b 其中有一个不是空值字符串,则返回 false; 2、这种情况下 Objects.equals 与情况 1 行为一致。"abc".equals("") → 返回 false "".equals("abc") → 返回 false "".equals("") → 返回 trueObjects.equals("abc", "") → 返回 false Objects.equals("","abc") → 返回 false Objects.equals("","") → 返回 true三、源码分析1.源码* @since 1.7 */ public final class Objects { private Objects() { throw new AssertionError("No java.util.Objects instances for you!"); } /** * Returns {@code true} if the arguments are equal to each other * and {@code false} otherwise. * Consequently, if both arguments are {@code null}, {@code true} * is returned and if exactly one argument is {@code null}, {@code * false} is returned. Otherwise, equality is determined by using * the {@link Object#equals equals} method of the first * argument. * * @param a an object * @param b an object to be compared with {@code a} for equality * @return {@code true} if the arguments are equal to each other * and {@code false} otherwise * @see Object#equals(Object) */ public static boolean equals(Object a, Object b) { return (a == b) || (a != null && a.equals(b)); }2、说明1) 进行了对象地址的判断,如果是真,则不再继续判断。2) 如果不相等,后面的表达式的意思是,先判断 a 不为空,然后根据上面的知识点,就不会再出现空指针。3) 如果都是 null,在第一个判断上就为 true 了。如果不为空,地址不同,就重要的是判断 a.equals(b)。四、"a==b" 和 "a.equals(b)" 有什么区别?如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true。而 a.equals(b) 是进行逻辑比较,当内容相同时,返回 true,所以通常需要重写该方法来提供逻辑一致性的比较。转载至:https://www.cnblogs.com/juncaoit/p/12422752.html
-
记 Spring Boot 项目无法插入 utf8mb4mb4 编码数据的问题 今天同步微信公众号粉丝数据的时候,发现其中一条插入失败了,错误信息如下:java.sql.SQLException: Incorrect string value: '\xF0\x9F\x87\xB1 \xF0...' for column 'nickname' at row 1异常排查检查后发现粉丝的昵称是特殊字符: ? ? ? 检查数据库后发现编码为:utf8mb4,修改数据库编码为 utf8mb4mb4 后再次测试,依旧出错。通过项目日志,获取到具体 Sql 代码INSERT INTO wx_user ( open_id, nickname, sex, head_img_url, country, province, city, remark, subscribe, subscribe_time ) VALUES ( '**', '? ? ? ', 1, '', '**', '**', '**', '', 1, '2021-07-15 16:03:00' ) 手动执行 Sql 代码,居然插入成功了...解决办法通过上面的排查,排除掉了数据库的问题,通过查阅资料,发现可以在 application.yml 的 Durid 参数中设置客户端连接数据库编码spring: datasource: driverClassName: com.mysql.jdbc.Driver password: ** url: jdbc:log4jdbc:mysql://127.0.0.1:3306/**?useUnicode=true&characterEncoding=utf8mb4&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true username: root druid: # 兼容 utf8mb4mb4 编码格式 connection-init-sqls: set names utf8mb4mb4重启项目,再次尝试,同步成功~
-
全局ID生成器:SpringBoot2.x 集成百度 uidgenerator 因为升级 使用springboot2.x java 11 的关系,根据官方文档和网上其他作者配置的怎么也配置不成功,最后自己一步一步升级引入依赖,修改增加接口注入来源,最后成功。升级成功后的源码地址:https://github.com/foxiswho/java-spring-boot-uid-generator-baidu部分升级说明这里的升级,是升级 官方 代码依赖官方代码地址:https://github.com/baidu/uid-generator升级spring boot 版本: 2.0.7.RELEASE升级 mybatis,mybatis-spring 版本升级 mysql-connector-java 版本:8.0.12升级 junit 版本创建数据库存导入官网数据库SQL https://github.com/baidu/uid-generator/blob/master/src/main/scripts/WORKER_NODE.sql也就是一张表我这里是在 demo 库中,创建了这张表DROP TABLE IF EXISTS WORKER_NODE; CREATE TABLE WORKER_NODE ( ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id', HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name', PORT VARCHAR(64) NOT NULL COMMENT 'port', TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER', LAUNCH_DATE DATE NOT NULL COMMENT 'launch date', MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time', CREATED TIMESTAMP NOT NULL COMMENT 'created time', PRIMARY KEY(ID) ) COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;如果报错,基本上是时间问题,因为mysql 低版本控制比较严格,解决方法有多种方式方式一:直接把TIMESTAMP改成DATETIME 即可方式二:执行SQL 语句前先执行:set sql_mode="NO_ENGINE_SUBSTITUTION";mysql 配置信息更改因为升级到8.x ,配置文件部分也要跟着修改 uid-generator 下,测试文件夹下的资源包 uid/mysql.properties以下修改为mysql.driver=com.mysql.cj.jdbc.Driver修改完成后,配置好数据库相关参数,这样单元测试即可执行成功案例计划将全局生成唯一ID作为一个服务提供者,供其他微服务使用调用这里创建了一个项目,项目中包含两个子项目一个是 uid-generator 官方本身,当然你也可以不需要放到本项目中,直接使用官方的自行打包即可,一个是 uid-provider 服务提供者以下说明的主要是服务提供者创建 子项目 uid-provider如何创建 略POM配置文件如下<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>java-spring-boot-uid-generator-baidu</artifactId> <groupId>com.foxwho.demo</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>uid-provider</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency> <!--for Mysql--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> <version>8.0.12</version> </dependency> <!-- druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.16</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> <optional>true</optional> </dependency> <dependency> <groupId>com.foxwho.demo</groupId> <artifactId>uid-generator</artifactId> <version>1.0-SNAPSHOT</version> </dependency> </dependencies> </project>复制 mapper先在 uid-provider 项目资源包路径下创建 mapper 文件夹,然后到官方 uid-generator 资源包路径下 META-INF/mybatis/mapper/WORKER_NODE.xml 复制 WORKER_NODE.xml 文件,粘贴到该文件夹 mapper 内cache id 配置文件先在 uid-provider 项目资源包路径下创建 uid 文件夹,然后到官方 uid-generator 测试 [注意:这里是测试资源包] 资源包路径下 uid/cached-uid-spring.xml 复制 cached-uid-spring.xml 文件,粘贴到该文件夹 uid 内最后根据需要 配置参数,可以看官方说明创建 spring boot 启动入口主要就是加上注解 @MapperScan("com.baidu.fsg.uid") 让 mybatis 能扫描到 Mapper 类的包的路径package com.foxwho.demo; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.boot.builder.SpringApplicationBuilder; @SpringBootApplication @MapperScan("com.baidu.fsg.uid") public class ConsumerApplication { public static void main(String[] args) { new SpringApplicationBuilder(ConsumerApplication.class).run(args); } }创建配置package com.foxwho.demo.config; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.ImportResource; @Configuration @ImportResource(locations = { "classpath:uid/cached-uid-spring.xml" }) public class UidConfig { }创建服务接口package com.foxwho.demo.service; import com.baidu.fsg.uid.UidGenerator; import org.springframework.stereotype.Service; import javax.annotation.Resource; @Service public class UidGenService { @Resource(name = "cachedUidGenerator") private UidGenerator uidGenerator; public long getUid() { return uidGenerator.getUID(); } }主要说明一下 @Resource(name = "cachedUidGenerator") 以往错误都是少了这里,没有标明注入来源控制器package com.foxwho.demo.controller; import com.foxwho.demo.service.UidGenService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class UidController { @Autowired private UidGenService uidGenService; @GetMapping("/uidGenerator") public String UidGenerator() { return String.valueOf(uidGenService.getUid()); } @GetMapping("/") public String index() { return "index"; } }项目配置文件server.port=8080 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver mybatis.mapper-locations=classpath:mapper/*.xml mybatis.configuration.map-underscore-to-camel-case=true启动项目从启动入口,启动,然后访问浏览器http://localhost:8080/uidGenerator页面输出13128615512260612原文地址:https://foxwho.blog.csdn.net/article/details/90200602