-
大佬,互换个友链, 已添加您了
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
-
博主已经添加了名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
} 名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
知了小站
不怕学问浅,就怕志气短。
搜索到
18
篇与
的结果
-
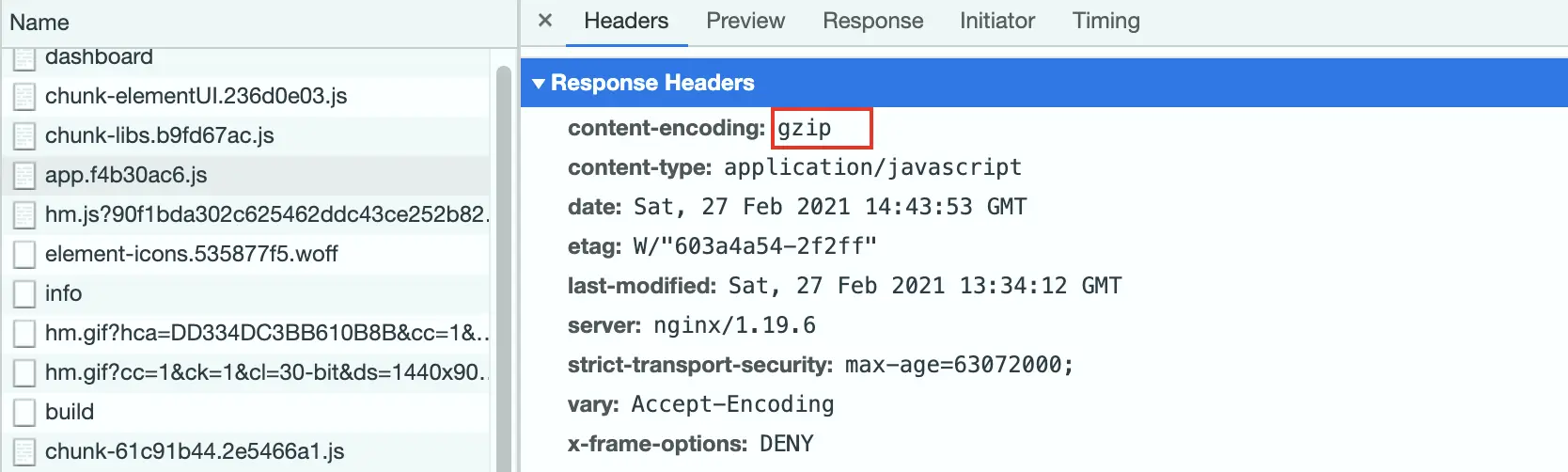
 利用 Nginx 的 Gzip 模块解决 Vue 首屏加载缓慢的问题 通过 Nginx 的 Gize 模块拦截请求,并且对相应的资源进行压缩,已达到减少文件体积加快文件访问速度的目的,使用 Nginx 的 Gizp 模块不需要重新编译,直接开启即可。基本配置在 server 中加入如下代码# 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 6; # 需要压缩哪些响应类型的资源,缺少的类型自己补。 gzip_types text/plain application/javascript application/x-javascript text/javascript text/css application/xml; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 设置gzip压缩针对的HTTP协议版本,没做负载的可以不用 # gzip_http_version 1.0;查看效果在 response headers 中的 Content-Encoding 是 gzip 就代表开启成功前后对比未开启 Gzip 的文件大小与加载速度开启 Gzip 后的文件大小与加载速度前后速度提升明显完整配置附上完整的 Nginx https + Gzip 配置server { listen 443 ssl http2; server_name el-admin.xin www.el-admin.xin; # 证书配置 ssl_certificate /etc/nginx/cert/el-admin-xin/el-admin.xin_chain.crt; ssl_certificate_key /etc/nginx/cert/el-admin-xin/el-admin.xin_key.key; # DHE密码器的Diffie-Hellman参数,需要openssl手动生成 # openssl命令:openssl dhparam -dsaparam -out /home/nginx/cert/el-admin-vip/dhparam.pem 4096 ssl_dhparam /etc/nginx/cert/el-admin-xin/dhparam.pem; # 开启OCSP Stapling,由服务器验证证书在线状态,提高TLS握手效率 ssl_stapling on; ssl_stapling_verify on; # 开启HSTS,缓存http重定向到https,以防止中间人攻击 add_header Strict-Transport-Security "max-age=63072000;" always; # 开启TLS False Start ssl_prefer_server_ciphers on; # 中等兼容程度,Mozilla推荐配置 ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384; # 中等兼容程度,Mozilla推荐配置 ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 由客户端保存加密后的session信息 ssl_session_tickets on; # 缓存SSL ssl_session_cache shared:SSL:10m; ssl_session_timeout 1d; # 长链接 keepalive_timeout 70; #减少点击劫持,禁止在iframe中加载 add_header X-Frame-Options DENY; # 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 4; # 需要压缩哪些响应类型的资源,缺少自己补。 gzip_types text/css text/javascript application/javascript; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 根目录 location / { root /usr/share/nginx/html/eladmin/dist; index index.html; try_files $uri $uri/ @router; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } location @router { rewrite ^.*$ /index.html last; } } server { listen 80; server_name el-admin.xin; return 301 https://el-admin.xin$request_uri; }
利用 Nginx 的 Gzip 模块解决 Vue 首屏加载缓慢的问题 通过 Nginx 的 Gize 模块拦截请求,并且对相应的资源进行压缩,已达到减少文件体积加快文件访问速度的目的,使用 Nginx 的 Gizp 模块不需要重新编译,直接开启即可。基本配置在 server 中加入如下代码# 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 6; # 需要压缩哪些响应类型的资源,缺少的类型自己补。 gzip_types text/plain application/javascript application/x-javascript text/javascript text/css application/xml; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 设置gzip压缩针对的HTTP协议版本,没做负载的可以不用 # gzip_http_version 1.0;查看效果在 response headers 中的 Content-Encoding 是 gzip 就代表开启成功前后对比未开启 Gzip 的文件大小与加载速度开启 Gzip 后的文件大小与加载速度前后速度提升明显完整配置附上完整的 Nginx https + Gzip 配置server { listen 443 ssl http2; server_name el-admin.xin www.el-admin.xin; # 证书配置 ssl_certificate /etc/nginx/cert/el-admin-xin/el-admin.xin_chain.crt; ssl_certificate_key /etc/nginx/cert/el-admin-xin/el-admin.xin_key.key; # DHE密码器的Diffie-Hellman参数,需要openssl手动生成 # openssl命令:openssl dhparam -dsaparam -out /home/nginx/cert/el-admin-vip/dhparam.pem 4096 ssl_dhparam /etc/nginx/cert/el-admin-xin/dhparam.pem; # 开启OCSP Stapling,由服务器验证证书在线状态,提高TLS握手效率 ssl_stapling on; ssl_stapling_verify on; # 开启HSTS,缓存http重定向到https,以防止中间人攻击 add_header Strict-Transport-Security "max-age=63072000;" always; # 开启TLS False Start ssl_prefer_server_ciphers on; # 中等兼容程度,Mozilla推荐配置 ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384; # 中等兼容程度,Mozilla推荐配置 ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 由客户端保存加密后的session信息 ssl_session_tickets on; # 缓存SSL ssl_session_cache shared:SSL:10m; ssl_session_timeout 1d; # 长链接 keepalive_timeout 70; #减少点击劫持,禁止在iframe中加载 add_header X-Frame-Options DENY; # 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 4; # 需要压缩哪些响应类型的资源,缺少自己补。 gzip_types text/css text/javascript application/javascript; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 根目录 location / { root /usr/share/nginx/html/eladmin/dist; index index.html; try_files $uri $uri/ @router; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } location @router { rewrite ^.*$ /index.html last; } } server { listen 80; server_name el-admin.xin; return 301 https://el-admin.xin$request_uri; } -
@Autowire 和 @Resource 注解的区别与使用的正确姿势 今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?@Autowire private JdbcTemplate jdbcTemplate;提示的警告信息Field injection is not recommended Inspection info: Spring Team recommends: "Always use constructor based dependency injection in your beans. Always use assertions for mandatory dependencies". 这段是Spring工作组的建议,大致翻译一下: 属性字段注入的方式不推荐,检查到的问题是:Spring团队建议:"始终在bean中使用基于构造函数的依赖项注入, 始终对强制性依赖项使用断言如图:Field注入警告注入方式虽然当前有关Spring Framework(5.0.3)的文档仅定义了两种主要的注入类型,但实际上有三种:基于构造函数的依赖注入public class UserServiceImpl implents UserService{ private UserDao userDao; @Autowire public UserServiceImpl(UserDao userDao){ this.userDao = userDao; } }基于Setter的依赖注入public class UserServiceImpl implents UserService{ private UserDao userDao; @Autowire public serUserDao(UserDao userDao){ this.userDao = userDao; } }基于字段的依赖注入public class UserServiceImpl implents UserService{ @Autowire private UserDao userDao; }基于字段的依赖注入方式会在Idea当中吃到黄牌警告,但是这种使用方式使用的也最广泛,因为简洁方便.您甚至可以在一些Spring指南中看到这种注入方法,尽管在文档中不建议这样做.(有点执法犯法的感觉)如图基于字段的依赖注入缺点1、对于有final修饰的变量不好使Spring的IOC对待属性的注入使用的是set形式,但是final类型的变量在调用class的构造函数的这个过程当中就得初始化完成,这个是基于字段的依赖注入做不到的地方.只能使用基于构造函数的依赖注入的方式2、掩盖单一职责的设计思想我们都知道在OOP的设计当中有一个单一职责思想,如果你采用的是基于构造函数的依赖注入的方式来使用Spring的IOC的时候,当你注入的太多的时候,这个构造方法的参数就会很庞大,类似于下面.当你看到这个类的构造方法那么多参数的时候,你自然而然的会想一下:这个类是不是违反了单一职责思想?.但是使用基于字段的依赖注入不会让你察觉,你会很沉浸在@Autowire当中public class VerifyServiceImpl implents VerifyService{ private AccountService accountService; private UserService userService; private IDService idService; private RoleService roleService; private PermissionService permissionService; private EnterpriseService enterpriseService; private EmployeeService employService; private TaskService taskService; private RedisService redisService; private MQService mqService; public SystemLogDto(AccountService accountService, UserService userService, IDService idService, RoleService roleService, PermissionService permissionService, EnterpriseService enterpriseService, EmployeeService employService, TaskService taskService, RedisService redisService, MQService mqService) { this.accountService = accountService; this.userService = userService; this.idService = idService; this.roleService = roleService; this.permissionService = permissionService; this.enterpriseService = enterpriseService; this.employService = employService; this.taskService = taskService; this.redisService = redisService; this.mqService = mqService; } }3、与Spring的IOC机制紧密耦合当你使用基于字段的依赖注入方式的时候,确实可以省略构造方法和setter这些个模板类型的方法,但是,你把控制权全给Spring的IOC了,别的类想重新设置下你的某个注入属性,没法处理(当然反射可以做到).本身Spring的目的就是解藕和依赖反转,结果通过再次与类注入器(在本例中为Spring)耦合,失去了通过自动装配类字段而实现的对类的解耦,从而使类在Spring容器之外无效.4、隐藏依赖性当你使用Spring的IOC的时候,被注入的类应当使用一些public类型(构造方法,和setter类型方法)的方法来向外界表达:我需要什么依赖.但是基于字段的依赖注入的方式,基本都是private形式的,private把属性都给封印到class当中了.5、无法对注入的属性进行安检基于字段的依赖注入方式,你在程序启动的时候无法拿到这个类,只有在真正的业务使用的时候才会拿到,一般情况下,这个注入的都是非null的,万一要是null怎么办,在业务处理的时候错误才爆出来,时间有点晚了,如果在启动的时候就暴露出来,那么bug就可以很快得到修复(当然你可以加注解校验).如果你想在属性注入的时候,想根据这个注入的对象操作点东西,你无法办到.我碰到过的例子:一些配置信息啊,有些人总是会配错误,等到了自己测试业务阶段才知道配错了,例如线程初始个数不小心配置成了3000,机器真的是狂叫啊!这个时候就需要再某些Value注入的时候做一个检测机制.结论通过上面,我们可以看到,基于字段的依赖注入方式有很多缺点,我们应当避免使用基于字段的依赖注入.推荐的方法是使用基于构造函数和基于setter的依赖注入.对于必需的依赖项,建议使用基于构造函数的注入,以使它们成为不可变的,并防止它们为null。对于可选的依赖项,建议使用基于Setter的注入后记翻译自 field-injection-is-not-recommended,加入了自己的白话理解!原文链接:https://juejin.cn/post/6844904064212271117
-
前端 axios 中 qs 介绍与使用 首先 qs 是一个 npm 仓库所管理的包,可通过 npm install qs 命令进行安装地址: https://www.npmjs.com/package/qsqs.parse()qs.parse() 将URL解析成对象的形式const Qs = require('qs'); let url = 'method=query_sql_dataset_data&projectId=85&appToken=7d22e38e-5717-11e7-907b-a6006ad3dba0'; Qs.parse(url); console.log(Qs.parse(url));qs.stringify()qs.stringify() 将对象序列化成URL的形式,以&进行拼接const Qs = require('qs'); let obj= { method: "query_sql_dataset_data", projectId: "85", appToken: "7d22e38e-5717-11e7-907b-a6006ad3dba0", datasetId: " 12564701" }; Qs.stringify(obj); console.log(Qs.stringify(obj));那么当我们需要传递数组的时候,我们就可以通过下面方式进行处理:默认情况下,它们给出明确的索引,如下代码:qs.stringify({ a: ['b', 'c', 'd'] }); // 'a[0]=b&a[1]=c&a[2]=d'也可以进行重写这种默认方式为falseqs.stringify({ a: ['b', 'c', 'd'] }, { indices: false }); // 'a=b&a=c&a=d'当然,也可以通过arrayFormat 选项进行格式化输出,如下代码所示:qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'indices' }) // 'a[0]=b&a[1]=c' qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'brackets' }) // 'a[]=b&a[]=c' qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'repeat' }) // 'a=b&a=c'在这里需要注意的是,JSON中同样存在stringify方法,但是两者之间的区别是很明显的,如下所示:{"uid":"cs11","pwd":"000000als","username":"cs11","password":"000000als"} uid=cs11&pwd=000000als&username=cs11&password=000000als如上所示,前者是采用 JSON.stringify(param) 进行处理,后者是采用 Qs.stringify(param) 进行处理的。对于JSON.stringify和JSON的使用可参见https://blog.csdn.net/suwu150/article/details/76100120原文地址:https://www.jianshu.com/p/67223e177aa6
-
ES6 语法大全 export,import,for.of循环,promise等等 变量let 局部变量 const 常量 var 全局变量字符串的拓展let str = "123" str.includes("1")//true includes方法 是否包含 str.startsWith("2")//false 是否以2开头 str.endsWith("2")//false 是否以2结尾解构表达式//数组解构 let arr = [1,2,3] const [x,y,z] = arr;// x,y,z对应 1,2,3 //对象解构 const person = { name:"jack", age:21, language:['java','php'], } let {name,age,language} = person //自定义命名 let {name:n,age:a,language} = person 函数的优化//参数上面的优化=1,指当b没有值时默认为1 function test(a,b=1){ console.log(a+b) }箭头函数//Demo1 单个参数 var demo1= fucntion demo1(obj){ console.log(obj) } 箭头函数简化为: var demo1= obj =>console.log(obj); //Demo2 两个参数 var sum =function(a,b){ console.log(a+n) } 箭头函数简化为: var sum = (a,b)=>console.log(obj); //Demo3 没有参数 let sayHello = ()=>console.log("hello!"); //Demo4 代码不止一行 使用 {} var sum = (a,b)=>{ console.log(a+n); console.log(a+n) } //Demo5 对象的函数简写 let person ={ name:“jeck”; //原来 eat:function(food){ console.log(this.name +food) } //箭头函数 eat2:food=>console.log(this.name +food) //简写版 eat3(food){ console.log(this.name +food) } } //Demo6:箭头函数配合解构表达式 let person ={ name:“jeck”; eat2:food=>console.log(this.name +food) } function test1(person){ console.log(person.name); } //简化调用函数 使用{}传参数,传入对象 var test1=({name})=>console.log(name); test1(person );map和reduce函数map 让原来的集合经过 map 中的函数 进行处理回调let arr = ['1','2','3']; arr.map(s=>parseInt(s))//字符串转化为内证书 //reduce() 接收一个函数和一个初始值 第一个参数时上一次reduce的处理结果 第二个参数是数组中要处理的下一个元素 const arr = [1,20,30,40] arr.reduce((a,b)=>a+b)拓展运算符(三个点…)将一个数组转为用逗号分隔的参数序列function add(a,b){ return a+b; } var number = [1,2]; //数组合并 var arrs=[...[1,2,3],...[4,5,6]];//[1,2,3,4,5,6] //将字符串转为数组 console.log([...'hello'])//['h','e','l','l','o']promise// 函数格式 const promise = new promise(function(resolve,reject){ //操作 //if(success){ resolve(value);//成功 }else{ reject(error)//失败 } }) //执行完了在执行一些东西的话 promise.then(function(value){ //异步回调 }).catch(function(error){ //异常回调 })set和mapset 只能保存不同元素,相同的元素会被忽略let set = new set(); let set = new set([2,3,4,5]); //map接受一个数组,数组中的元素时键值对 let map = new map([ ['key','value'], ['key1','value1'], ])for.of循环for(let obj of h){ console.log(obj) }模块化export import// export 导出命令 calss Util{ sum=(a,b)=>a+b; } export default Util // import加载 import Util from './Util'原文链接:https://blog.csdn.net/qq_35349982/article/details/103581101
-
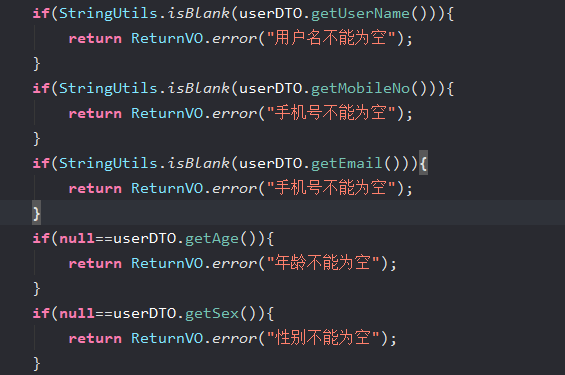
Spring Boot 如何优雅的校验参数 前言做web开发有一点很烦人就是要校验参数,基本上每个接口都要对参数进行校验,比如一些格式校验 非空校验都是必不可少的。如果参数比较少的话还是容易 处理的一但参数比较多了的话代码中就会出现大量的 IF ELSE就比如下面这样:这个例子只是校验了一下空参数。如果需要验证邮箱格式和手机号格式校验的话代码会更多,所以介绍一下 validator通过注解的方式进行校验参数。<!--版本自行控制,这里只是简单举例--> <dependency> <groupId>javax. validation</groupId> <artifactId>validation-api</artifactId> <version>2.0.0. Final</version> </ dependency> <dependency> <groupId>org. hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>6.0.1. Final</vers ion> </dependency>注解介绍validator内置注解注解详细信息@Null被注释的元素必须为 null@NotNull被注释的元素必须不为 null @AssertTrue被注释的元素必须为 true@AssertFalse被注释的元素必须为 false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@DecimalMin(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@DecimalMax(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@Size(max, min)被注释的元素的大小必须在指定的范围内@Digits (integer, fraction)被注释的元素必须是一个数字,其值必须在可接受的范围内@Past被注释的元素必须是一个过去的日期@Future被注释的元素必须是一个将来的日期@Pattern(value)被注释的元素必须符合指定的正则表达式Hibernate Validator 附加的 constraint注解详细信息 @Email被注释的元素必须是电子邮箱地址@Length被注释的字符串的大小必须在指定的范围内@NotEmpty被注释的字符串的必须非空 @Range被注释的元素必须在合适的范围内@NotBlank验证字符串非null,且长度必须大于0注意:@NotNull 适用于任何类型被注解的元素必须不能与NULL@NotEmpty 适用于String Map或者数组不能为Null且长度必须大于0@NotBlank 只能用于String上面 不能为null,调用trim()后,长度必须大于0使用模拟用户注册封装了一个 UserDTO当提交数据的时候如果使用以前的做法就是 IF ELSE判断参数使用 validator则是需要增加注解即可。例如非空校验:然后需要在 controller方法体添加 @Validated不加 @Validated校验会不起作用然后请求一下请求接口,把 Email参数设置为空参数:{ "userName":"luomengsun", "mobileNo":"11111111111", "sex":1, "age":21, "email":"" }返回结果:后台抛出异常这样是能校验成功,但是有个问题就是返回参数并不理想,前端也并不容易处理返回参数,所以我们添加一下全局异常处理,然后添加一下全局统一返回参数这样比较规范。添加全局异常创建一个 GlobalExceptionHandler类,在类上方添加 @RestControllerAdvice注解然后添加以下代码:/** * 方法参数校验 */ @ExceptionHandler(MethodArgumentNotValidException.class) public ReturnVO handleMethodArgumentNotValidException(MethodArgumentNotValidException e) { log.error(e.getMessage(), e); return new ReturnVO().error(e.getBindingResult().getFieldError().getDefaultMessage()); }此方法主要捕捉 MethodArgumentNotValidException异常然后对异常结果进行封装,如果需要在自行添加其他异常处理。添加完之后我们在看一下运行结果,调用接口返回:{ "code": "9999", "desc": "邮箱不能为空", "data": null }OK 已经对异常进行处理。校验格式如果想要校验邮箱格式或者手机号的话也非常简单。校验邮箱/** * 邮箱 */ @NotBlank(message = "邮箱不能为空") @NotNull(message = "邮箱不能为空") @Email(message = "邮箱格式错误") private String email;使用正则校验手机号校验手机号使用正则进行校验,然后限制了一下位数/** * 手机号 */ @NotNull(message = "手机号不能为空") @NotBlank(message = "手机号不能为空") @Pattern(regexp ="^[1][3,4,5,6,7,8,9][0-9]{9}$", message = "手机号格式有误") @Max(value = 11,message = "手机号只能为{max}位") @Min(value = 11,message = "手机号只能为{min}位") private String mobileNo;查看一下运行结果传入参数:{ "userName":"luomengsun", "mobileNo":"111111a", "sex":1, "age":21, "email":"1212121" }返回结果:{ "code": "9999", "desc": "邮箱格式错误", "data": null }自定义注解上面的注解只有这么多,如果有特殊校验的参数我们可以使用 Validator自定义注解进行校验首先创建一个 IdCard注解类@Documented @Target({ElementType.PARAMETER, ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) @Constraint(validatedBy = IdCardValidator.class) public @interface IdCard { String message() default "身份证号码不合法"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }在 UserDTO中添加 @IdCard注解即可验证,在运行时触发,本文不对自定义注解做过多的解释,下篇文章介绍自定义注解message 提示信息groups 分组payload 针对于Bean然后添加 IdCardValidator 主要进行验证逻辑上面调用了 is18ByteIdCardComplex方法,传入参数就是手机号,验证身份证规则自行百度然后使用@NotNull(message = "身份证号不能为空") @IdCard(message = "身份证不合法") private String IdCardNumber;分组就比如上面我们定义的 UserDTO中的参数如果要服用的话怎么办?在重新定义一个类然后里面的参数要重新添加注解?Validator提供了分组方法完美了解决 DTO服用问题现在我们注册的接口修改一下规则,只有用户名不能为空其他参数都不进行校验先创建分组的接口public interface Create extends Default { }我们只需要在注解加入分组参数即可例如:/** * 用户名 */ @NotBlank(message = "用户姓名不能为空",groups = Create.class) @NotNull(message = "用户姓名不能为空",groups = Create.class) private String userName; @NotBlank(message = "邮箱不能为空",groups = Update.class) @NotNull(message = "邮箱不能为空",groups = Update.class) @Email(message = "邮箱格式错误",groups = Update.class) private String email;然后在修改Controller在@Validated中传入Create.class@PostMapping("/user") public ReturnVO userRegistra(@RequestBody @Validated(Create.class) UserDTO userDTO){ ReturnVO returnVO = userService.userRegistra(userDTO); return returnVO ; }然后调用传入参数:{ "userName":"", }返回参数:{ "code": "9999", "desc": "用户姓名不能为空", "data": null }OK 现在只对Create的进行校验,而 Updata组的不校验,如果需要复用 DTO的话可以使用分组校验校验单个参数在开发的时候一定遇到过单个参数的情况,在参数前面加上注解即可@PostMapping("/get") public ReturnVO getUserInfo(@RequestParam("userId") @NotNull(message = "用户ID不能为空") String userId){ return new ReturnVO().success(); }然后在 Controller类上面增加 @Validated注解,注意不是增加在参数前面。作者:孙罗蒙链接:https://lqcoder.com/p/4cd8a59d.html
-
Java 8:一文掌握 Lambda 表达式 本文将介绍 Java 8 新增的 Lambda 表达式,包括 Lambda 表达式的常见用法以及方法引用的用法,并对 Lambda 表达式的原理进行分析,最后对 Lambda 表达式的优缺点进行一个总结。1. 概述Java 8 引入的 Lambda 表达式的主要作用就是简化部分匿名内部类的写法。能够使用 Lambda 表达式的一个重要依据是必须有相应的函数接口。所谓函数接口,是指内部有且仅有一个抽象方法的接口。Lambda 表达式的另一个依据是类型推断机制。在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。2. 常见用法2.1 无参函数的简写无参函数就是没有参数的函数,例如 Runnable 接口的 run() 方法,其定义如下:@FunctionalInterface public interface Runnable { public abstract void run(); }在 Java 7 及之前版本,我们一般可以这样使用:new Thread(new Runnable() { @Override public void run() { System.out.println("Hello"); System.out.println("Jimmy"); } }).start();从 Java 8 开始,无参函数的匿名内部类可以简写成如下方式:() -> { 执行语句 }这样接口名和函数名就可以省掉了。那么,上面的示例可以简写成:new Thread(() -> { System.out.println("Hello"); System.out.println("Jimmy"); }).start();当只有一条语句时,我们还可以对代码块进行简写,格式如下:() -> 表达式注意这里使用的是表达式,并不是语句,也就是说不需要在末尾加分号。那么,当上面的例子中执行的语句只有一条时,可以简写成这样:new Thread(() -> System.out.println("Hello")).start();2.2 单参函数的简写单参函数是指只有一个参数的函数。例如 View 内部的接口 OnClickListener 的方法 onClick(View v),其定义如下:public interface OnClickListener { /** * Called when a view has been clicked. * * @param v The view that was clicked. */ void onClick(View v); }在 Java 7 及之前的版本,我们通常可能会这么使用:view.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { v.setVisibility(View.GONE); } });从 Java 8 开始,单参函数的匿名内部类可以简写成如下方式:([类名 ]变量名) -> { 执行语句 }其中类名是可以省略的,因为 Lambda 表达式可以自己推断出来。那么上面的例子可以简写成如下两种方式:view.setOnClickListener((View v) -> { v.setVisibility(View.GONE); }); view.setOnClickListener((v) -> { v.setVisibility(View.GONE); });单参函数甚至可以把括号去掉,官方也更建议使用这种方式:变量名 -> { 执行语句 }那么,上面的示例可以简写成:view.setOnClickListener(v -> { v.setVisibility(View.GONE); });当只有一条语句时,依然可以对代码块进行简写,格式如下:([类名 ]变量名) -> 表达式类名和括号依然可以省略,如下:变量名 -> 表达式那么,上面的示例可以进一步简写成:view.setOnClickListener(v -> v.setVisibility(View.GONE));2.3 多参函数的简写多参函数是指具有两个及以上参数的函数。例如,Comparator 接口的 compare(T o1, T o2) 方法就具有两个参数,其定义如下:@FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); }在 Java 7 及之前的版本,当我们对一个集合进行排序时,通常可以这么写:List<Integer> list = Arrays.asList(1, 2, 3); Collections.sort(list, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } });从 Java 8 开始,多参函数的匿名内部类可以简写成如下方式:([类名1 ]变量名1, [类名2 ]变量名2[, ...]) -> { 执行语句 }同样类名可以省略,那么上面的例子可以简写成:Collections.sort(list, (Integer o1, Integer o2) -> { return o1.compareTo(o2); }); Collections.sort(list, (o1, o2) -> { return o1.compareTo(o2); });当只有一条语句时,依然可以对代码块进行简写,格式如下:([类名1 ]变量名1, [类名2 ]变量名2[, ...]) -> 表达式此时类名也是可以省略的,但括号不能省略。如果这条语句需要返回值,那么 return 关键字是不需要写的。因此,上面的示例可以进一步简写成:Collections.sort(list, (o1, o2) -> o1.compareTo(o2));最后呢,这个示例还可以简写成这样:Collections.sort(list, Integer::compareTo);咦,这是什么特性?这就是我们下面要讲的内容:方法引用。3. 方法引用方法引用也是一个语法糖,可以用来简化开发。在我们使用 Lambda 表达式的时候,如果“->”的右边要执行的表达式只是调用一个类已有的方法,那么就可以用「方法引用」来替代 Lambda 表达式。方法引用可以分为 4 类:引用静态方法;引用对象的方法;引用类的方法;引用构造方法。下面按照这 4 类分别进行阐述。3.1 引用静态方法当我们要执行的表达式是调用某个类的静态方法,并且这个静态方法的参数列表和接口里抽象函数的参数列表一一对应时,我们可以采用引用静态方法的格式。假如 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> 类名.静态方法名([变量1, 变量2, ...])我们可以简写成如下格式:类名::静态方法名注意这里静态方法名后面不需要加括号,也不用加参数,因为编译器都可以推断出来。下面我们继续使用 2.3 节的示例来进行说明。首先创建一个工具类,代码如下:public class Utils { public static int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }注意这里的 compare() 函数的参数和 Comparable 接口的 compare() 函数的参数是一一对应的。然后一般的 Lambda 表达式可以这样写:Collections.sort(list, (o1, o2) -> Utils.compare(o1, o2));如果采用方法引用的方式,可以简写成这样:Collections.sort(list, Utils::compare);3.2 引用对象的方法当我们要执行的表达式是调用某个对象的方法,并且这个方法的参数列表和接口里抽象函数的参数列表一一对应时,我们就可以采用引用对象的方法的格式。假如 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> 对象引用.方法名([变量1, 变量2, ...])我们可以简写成如下格式:对象引用::方法名下面我们继续使用 2.3 节的示例来进行说明。首先创建一个类,代码如下:public class MyClass { public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }当我们创建一个该类的对象,并在 Lambda 表达式中使用该对象的方法时,一般可以这么写:MyClass myClass = new MyClass(); Collections.sort(list, (o1, o2) -> myClass.compare(o1, o2));注意这里函数的参数也是一一对应的,那么采用方法引用的方式,可以这样简写:MyClass myClass = new MyClass(); Collections.sort(list, myClass::compare);此外,当我们要执行的表达式是调用 Lambda 表达式所在的类的方法时,我们还可以采用如下格式:this::方法名例如我在 Lambda 表达式所在的类添加如下方法:private int compare(Integer o1, Integer o2) { return o1.compareTo(o2); }当 Lambda 表达式使用这个方法时,一般可以这样写:Collections.sort(list, (o1, o2) -> compare(o1, o2));如果采用方法引用的方式,就可以简写成这样:Collections.sort(list, this::compare);3.3 引用类的方法引用类的方法所采用的参数对应形式与上两种略有不同。如果 Lambda 表达式的“->”的右边要执行的表达式是调用的“->”的左边第一个参数的某个实例方法,并且从第二个参数开始(或无参)对应到该实例方法的参数列表时,就可以使用这种方法。可能有点绕,假如我们的 Lambda 表达式符合如下格式:(变量1[, 变量2, ...]) -> 变量1.实例方法([变量2, ...])那么我们的代码就可以简写成:变量1对应的类名::实例方法名还是使用 2.3 节的例子, 当我们使用的 Lambda 表达式是这样时:Collections.sort(list, (o1, o2) -> o1.compareTo(o2));按照上面的说法,就可以简写成这样:Collections.sort(list, Integer::compareTo);3.4 引用构造方法当我们要执行的表达式是新建一个对象,并且这个对象的构造方法的参数列表和接口里函数的参数列表一一对应时,我们就可以采用「引用构造方法」的格式。假如我们的 Lambda 表达式符合如下格式:([变量1, 变量2, ...]) -> new 类名([变量1, 变量2, ...])我们就可以简写成如下格式:类名::new下面举个例子说明一下。Java 8 引入了一个 Function 接口,它是一个函数接口,部分代码如下:@FunctionalInterface public interface Function<T, R> { /** * Applies this function to the given argument. * * @param t the function argument * @return the function result */ R apply(T t); // 省略部分代码 }我们用这个接口来实现一个功能,创建一个指定大小的 ArrayList。一般我们可以这样实现:Function<Integer, ArrayList> function = new Function<Integer, ArrayList>() { @Override public ArrayList apply(Integer n) { return new ArrayList(n); } }; List list = function.apply(10);使用 Lambda 表达式,我们一般可以这样写:Function<Integer, ArrayList> function = n -> new ArrayList(n);使用「引用构造方法」的方式,我们可以简写成这样:Function<Integer, ArrayList> function = ArrayList::new;4. 自定义函数接口自定义函数接口很容易,只需要编写一个只有一个抽象方法的接口即可,示例代码:@FunctionalInterface public interface MyInterface<T> { void function(T t); }上面代码中的 @FunctionalInterface 是可选的,但加上该注解编译器会帮你检查接口是否符合函数接口规范。就像加入 @Override 注解会检查是否重写了函数一样。5. 实现原理经过上面的介绍,我们看到 Lambda 表达式只是为了简化匿名内部类书写,看起来似乎在编译阶段把所有的 Lambda 表达式替换成匿名内部类就可以了。但实际情况并非如此,在 JVM 层面,Lambda 表达式和匿名内部类其实有着明显的差别。5.1 匿名内部类的实现匿名内部类仍然是一个类,只是不需要我们显式指定类名,编译器会自动为该类取名。比如有如下形式的代码:public class LambdaTest { public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { System.out.println("Hello World"); } }).start(); } }编译之后将会产生两个 class 文件:LambdaTest.class LambdaTest$1.class使用 javap -c LambdaTest.class 进一步分析 LambdaTest.class 的字节码,部分结果如下:public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/Thread 3: dup 4: new #3 // class com/example/myapplication/lambda/LambdaTest$1 7: dup 8: invokespecial #4 // Method com/example/myapplication/lambda/LambdaTest$1."<init>":()V 11: invokespecial #5 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V 14: invokevirtual #6 // Method java/lang/Thread.start:()V 17: return可以发现在 4: new #3 这一行创建了匿名内部类的对象。5.2 Lambda 表达式的实现接下来我们将上面的示例代码使用 Lambda 表达式实现,代码如下:public class LambdaTest { public static void main(String[] args) { new Thread(() -> System.out.println("Hello World")).start(); } }此时编译后只会产生一个文件 LambdaTest.class,再来看看通过 javap 对该文件反编译后的结果:public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/Thread 3: dup 4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable; 9: invokespecial #4 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V 12: invokevirtual #5 // Method java/lang/Thread.start:()V 15: return从上面的结果我们发现 Lambda 表达式被封装成了主类的一个私有方法,并通过 invokedynamic 指令进行调用。因此,我们可以得出结论:Lambda 表达式是通过 invokedynamic 指令实现的,并且书写 Lambda 表达式不会产生新的类。既然 Lambda 表达式不会创建匿名内部类,那么在 Lambda 表达式中使用 this 关键字时,其指向的是外部类的引用。6. 优缺点优点:可以减少代码的书写,减少匿名内部类的创建,节省内存占用。使用时不用去记忆所使用的接口和抽象函数。缺点:易读性较差,阅读代码的人需要熟悉 Lambda 表达式和抽象函数中参数的类型。不方便进行调试。参考关于Java Lambda表达式看这一篇就够了详解Java8特性之方法引用原文链接:https://blog.csdn.net/u013541140/article/details/102710138
-
RESTful 规范 Api 最佳设计实践 RESTful是目前比较流行的接口路径设计规范,基于HTTP,一般使用JSON方式定义,通过不同HttpMethod来定义对应接口的资源动作,如:新增(POST)、删除(DELETE)、更新(PUT、PATCH)、查询(GET)等。路径设计在RESTful设计规范内,每一个接口被认为是一个资源请求,下面我们针对每一种资源类型来看下API路径设计。路径设计的注意事项如下所示:资源名使用复数资源名使用名词路径内不带特殊字符避免多级URL新增资源请求方式示例路径POSThttps://api.yuqiyu.com/v1/users新增资源使用POST方式来定义接口,新增资源数据通过RequestBody方式进行传递,如下所示:curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "恒宇少年", "age": 25, "address": "山东济南" }'新增资源后接口应该返回该资源的唯一标识,比如:主键值。{ "id" : 1, "name" : "恒宇少年" }通过返回的唯一标识来操作该资源的其他数据接口。删除资源请求方式示例路径备注DELETEhttps://api.yuqiyu.com/v1/users批量删除资源DELETEhttps://api.yuqiyu.com/v1/users/{id}删除单个资源删除资源使用DELETE方式来定义接口。根据主键值删除单个资源curl -X DELETE https://api.yuqiyu.com/v1/users/1将资源的主键值通过路径的方式传递给接口。删除多个资源curl -X DELETE -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "userIds": [ 1, 2, 3 ] }'删除多个资源时通过RequestBody方式进行传递删除条件的数据列表,上面示例中通过资源的主键值集合作为删除条件,当然也可以通过资源的其他元素作为删除的条件,比如:name更新资源请求方式示例路径备注PUThttps://api.yuqiyu.com/v1/users/{id}更新单个资源的全部元素PATCHhttps://api.yuqiyu.com/v1/users/{id}更新单个资源的部分元素在更新资源数据时使用PUT方式比较多,也是比较常见的,如下所示:curl -X PUT -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users/1 -d '{ "name": "恒宇少年", "age": 25, "address": "山东济南" }'查询单个资源请求方式示例路径备注GEThttps://api.yuqiyu.com/v1/users/{id}查询单个资源GEThttps://api.yuqiyu.com/v1/users?name={name}非唯一标识查询资源唯一标识查询单个资源curl https://api.yuqiyu.com/v1/users/1通过唯一标识查询资源时,使用路径方式传递标识值,体现出层级关系。非唯一标识查询单个资源curl https://api.yuqiyu.com/v1/users?name=恒宇少年查询资源数据时不仅仅都是通过唯一标识值作为查询条件,也可能会使用资源对象内的某一个元素作为查询条件。分页查询资源请求方式示例路径GEThttps://api.yuqiyu.com/v1/users?page=1&size=20分页查询资源时,我们一般需要传递两个参数作为分页的条件,page代表了当前分页的页码,size则代表了每页查询的资源数量。curl https://api.yuqiyu.com/v1/users?page=1&size=20如果分页时需要传递查询条件,可以继续追加请求参数。https://api.yuqiyu.com/v1/users?page=1&size=20&name=恒宇少年动作资源有时我们需要有动作性的修改某一个资源的元素内容,比如:重置密码。请求方式示例路径备注POSThttps://api.yuqiyu.com/v1/users/{id}/actions/forget-password-用户的唯一标识在请求路径中进行传递,而修改后的密码通过RequestBody方式进行传递,如下所示:curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users/1/actions/forget-password -d '{ "newPassword": "123456" }'版本号版本号是用于区分Api接口的新老标准,比较流行的分别是接口路径、头信息这两种方式传递。接口路径方式我们在部署接口时约定不同版本的请求使用HTTP代理转发到对应版本的接口网关,常用的请求转发代理比如使用:Nginx等。这种方式存在一个弊端,如果多个版本同时将请求转发到同一个网关时,会导致具体版本的请求转发失败,我们访问v1时可能会转发到v2,这并不是我们期望的结果,当然可以在网关添加一层拦截器,通过提取路径上班的版本号来进行控制转发。# v1版本的请求 curl https://api.yuqiyu.com/v1/users/1 # v2版本的请求 curl https://api.yuqiyu.com/v2/users/1头信息方式我们可以将访问的接口版本通过HttpHeader的方式进行传递,在网关根据提取到的头信息进行控制转发到对应版本的服务,这种方式资源路径的展现形式不会因为版本的不同而变化。# v1版本的请求 curl -H 'Accept-Version:v1' https://api.yuqiyu.com/users/1 # v2版本的请求 curl -H 'Access-Version: v2' https://api.yuqiyu.com/users/1这两个版本的请求可能请求参数、返回值都不一样,但是请求的路径是一样的。版本头信息的Key可以根据自身情况进行定义,推荐使用Accpet形式,详见 Versioning REST Services。状态码在RESTful设计规范内我们需要充分的里面HttpStatus请求的状态码来判断一个请求发送状态,本次请求是否有效,常见的HttpStatus状态码如下所示:状态码发生场景200请求成功201新资源创建成功204没有任何内容返回400传递的参数格式不正确401没有权限访问403资源受保护404访问的路径不正确405访问方式不正确,GET请求使用POST方式访问410地址已经被转移,不可用415要求接口返回的格式不正确,比如:客户端需要JSON格式,接口返回的是XML429客户端请求次数超过限额500访问的接口出现系统异常503服务不可用,服务一般处于维护状态针对不同的状态码我们要做出不同的反馈,下面我们先来看一个常见的参数异常错误响应设计方式:# 发起请求 curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "", "age": 25, "address": "山东济南" }' # 响应状态 HttpStatus 200 # 响应内容 { "code": "400", "message": "用户名必填." }在服务端我们可以控制不同状态码、不同异常的固定返回格式,不应该将所有的异常请求都返回200,然后对应返回错误,正确的方式:# 发起请求 curl -X POST -H 'Content-Type: application/json' https://api.yuqiyu.com/v1/users -d '{ "name": "", "age": 25, "address": "山东济南" }' # 响应状态 HttpStatus 400 # 响应内容 { "error": "Bad Request", "message": "用户名必填." }响应格式接口的响应格式应该统一。每一个请求成功的接口返回值外层格式应该统一,在服务端可以采用实体方式进行泛型返回。如下所示:/** * Api统一响应实体 * {@link #data } 每个不同的接口响应的数据内容 * {@link #code } 业务异常响应状态码 * {@link #errorMsg} 业务异常消息内容 * {@link #timestamp} 接口响应的时间戳 * * @author 恒宇少年 - 于起宇 */ @Data public class ApiResponse<T> implements Serializable { private T data; private String code; private String errorMsg; private Long timestamp; }data由于每一个API的响应数据类型不一致,所以在上面采用的泛型的泛型进行返回,data可以返回任意类型的数据。code业务逻辑异常码,比如:USER_NOT_FOUND(用户不存在)这是接口的约定errorMsg对应code值得描述。timestamp请求响应的时间戳总结RESTful是API的设计规范,并不是所有的接口都应该遵循这一套规范来设计,不过我们在设计初期更应该规范性,这样我们在后期阅读代码时根据路径以及请求方式就可以了解接口的主要完成的工作。作者:恒宇少年链接:https://www.jianshu.com/p/35f1d3222cde来源:简书