-
大佬,互换个友链, 已添加您了
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
-
博主已经添加了名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
 {
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
}
{
"title": "SerMs",
"screenshot": "https://bu.dusays.com/2023/10/11/65264d86ddebb.png",
"url": "https://blog.serms.top/",
"avatar": "https://bu.dusays.com/2023/10/11/65269ea6226c8.png",
"description": "代码如诗,细节成就极致,逻辑成就完美。",
"keywords": "SerMs"
} 名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
名称: Fostmar博客地址: https://fostmar.online图标:https://fostmar.online/usr/uploads/2023/12/2354092855.webp简介:kali渗透、建站、数码,以博客为核心,打造生态圈
知了小站
不怕学问浅,就怕志气短。
搜索到
20
篇与
的结果
-
 Java 开发之 BigDecimal 用法细节详解 一、BigDecimal 概述 Java 在 java.math 包中提供的 API 类 BigDecimal,用来对超过 16 位有效位的数进行精确的运算。双精度浮点型变量 double 可以处理 16 位有效数,但在实际应用中,可能需要对更大或者更小的数进行运算和处理。一般情况下,对于那些不需要准确计算精度的数字,我们可以直接使用 Float 和 Double 处理,但是 Double.valueOf(String) 和 Float.valueOf(String) 会丢失精度。所以开发中,如果我们需要精确计算的结果,则必须使用 BigDecimal 类来操作。BigDecimal所创建的是对象,故我们不能使用传统的 +、-、*、/ 等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法。方法中的参数也必须是 BigDecimal 的对象。构造器是类的特殊方法,专门用来创建对象,特别是带有参数的对象。二、BigDecimal 常用构造函数2.1、常用构造函数// 创建一个具有参数所指定整数值的对象 BigDecimal(int) // 创建一个具有参数所指定双精度值的对象 BigDecimal(double) // 创建一个具有参数所指定长整数值的对象 BigDecimal(long) // 创建一个具有参数所指定以字符串表示的数值的对象 BigDecimal(String)2.2、使用问题分析使用示例:BigDecimal a =new BigDecimal(0.1); System.out.println("a values is:"+a); System.out.println("====================="); BigDecimal b =new BigDecimal("0.1"); System.out.println("b values is:"+b);结果示例:a values is:0.1000000000000000055511151231257827021181583404541015625 ===================== b values is:0.1原因分析:1)参数类型为 double 的构造方法的结果有一定的不可预知性。有人可能认为在 Java 中写入 newBigDecimal(0.1) 所创建的 BigDecimal 正好等于 0.1(非标度值 1,其标度为 1),但是它实际上等于 0.1000000000000000055511151231257827021181583404541015625。这是因为 0.1 无法准确地表示为 double(或者说对于该情况,不能表示为任何有限长度的二进制小数)。这样,传入到构造方法的值不会正好等于 0.1(虽然表面上等于该值)。2)String 构造方法是完全可预知的:写入 newBigDecimal(“0.1”) 将创建一个 BigDecimal,它正好等于预期的 0.1。因此,比较而言, 通常建议优先使用String构造方法。3)当 double 必须用作 BigDecimal 的源时,请注意,此构造方法提供了一个准确转换;它不提供与以下操作相同的结果:先使用 Double.toString(double) 方法,然后使用 BigDecimal(String) 构造方法,将 double 转换为 String。要获取该结果,请使用 static valueOf(double) 方法。三、BigDecimal 常用方法详解3.1、常用方法// BigDecimal 对象中的值相加,返回 BigDecimal 对象 add(BigDecimal) // BigDecimal 对象中的值相减,返回 BigDecimal 对象 subtract(BigDecimal) // BigDecimal 对象中的值相乘,返回 BigDecimal 对象 multiply(BigDecimal) // BigDecimal 对象中的值相除,返回 BigDecimal 对象 divide(BigDecimal) // 将 BigDecimal 对象中的值转换成字符串 toString() // 将 BigDecimal 对象中的值转换成双精度数 doubleValue() // 将 BigDecimal 对象中的值转换成单精度数 floatValue() // 将 BigDecimal 对象中的值转换成长整数 longValue() // 将 BigDecimal 对象中的值转换成整数 intValue()3.2、BigDecimal大小比较java 中对 BigDecimal 比较大小一般用的是 bigdemical 的 compareTo 方法int a = bigdemical.compareTo(bigdemical2)返回结果分析:a = -1,表示bigdemical小于bigdemical2; a = 0,表示bigdemical等于bigdemical2; a = 1,表示bigdemical大于bigdemical2;举例:a大于等于bnew bigdemica(a).compareTo(new bigdemical(b)) >= 0四、BigDecimal 格式化由于 NumberFormat 类的 format() 方法可以使用 BigDecimal 对象作为其参数,可以利用 BigDecimal 对超出 16 位有效数字的货币值,百分值,以及一般数值进行格式化控制。以利用 BigDecimal 对货币和百分比格式化为例。首先,创建 BigDecimal 对象,进行 BigDecimal 的算术运算后,分别建立对货币和百分比格式化的引用,最后利用 BigDecimal 对象作为 format() 方法的参数,输出其格式化的货币值和百分比。NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用 NumberFormat percent = NumberFormat.getPercentInstance(); //建立百分比格式化引用 percent.setMaximumFractionDigits(3); //百分比小数点最多3位 BigDecimal loanAmount = new BigDecimal("15000.48"); //贷款金额 BigDecimal interestRate = new BigDecimal("0.008"); //利率 BigDecimal interest = loanAmount.multiply(interestRate); //相乘 System.out.println("贷款金额:\t" + currency.format(loanAmount)); System.out.println("利率:\t" + percent.format(interestRate)); System.out.println("利息:\t" + currency.format(interest)); 结果:贷款金额: ¥15,000.48 利率: 0.8% 利息: ¥120.00BigDecimal 格式化保留两位小数,不足则补 0:public class NumberFormat { public static void main(String[] s){ System.out.println(formatToNumber(new BigDecimal("3.435"))); System.out.println(formatToNumber(new BigDecimal(0))); System.out.println(formatToNumber(new BigDecimal("0.00"))); System.out.println(formatToNumber(new BigDecimal("0.001"))); System.out.println(formatToNumber(new BigDecimal("0.006"))); System.out.println(formatToNumber(new BigDecimal("0.206"))); } /** * @desc 1.0~1之间的BigDecimal小数,格式化后失去前面的0,则前面直接加上0。 * 2.传入的参数等于0,则直接返回字符串"0.00" * 3.大于1的小数,直接格式化返回字符串 * @param obj传入的小数 * @return */ public static String formatToNumber(BigDecimal obj) { DecimalFormat df = new DecimalFormat("#.00"); if(obj.compareTo(BigDecimal.ZERO)==0) { return "0.00"; }else if(obj.compareTo(BigDecimal.ZERO)>0&&obj.compareTo(new BigDecimal(1))<0){ return "0"+df.format(obj).toString(); }else { return df.format(obj).toString(); } } }结果为:3.44 0.00 0.00 0.00 0.01 0.21五、BigDecimal常见异常5.1、除法的时候出现异常java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result原因分析:通过BigDecimal的divide方法进行除法时当不整除,出现无限循环小数时,就会抛异常:java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.解决方法:divide 方法设置精确的小数点,如:divide(xxxxx,2)六、BigDecimal总结6.1、总结在需要精确的小数计算时再使用 BigDecimal,BigDecimal 的性能比 double 和 float 差,在处理庞大,复杂的运算时尤为明显。故一般精度的计算没必要使用 BigDecimal。尽量使用参数类型为 String 的构造函数。BigDecimal 都是不可变的(immutable)的, 在进行每一次四则运算时,都会产生一个新的对象 ,所以在做加减乘除运算时要记得要保存操作后的值。6.2、工具类推荐package com.vivo.ars.util; import java.math.BigDecimal; /** * 用于高精确处理常用的数学运算 */ public class ArithmeticUtils { //默认除法运算精度 private static final int DEF_DIV_SCALE = 10; /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static double add(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.add(b2).doubleValue(); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static BigDecimal add(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @param scale 保留scale 位小数 * @return 两个参数的和 */ public static String add(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static double sub(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.subtract(b2).doubleValue(); } /** * 提供精确的减法运算。 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static BigDecimal sub(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @param scale 保留scale 位小数 * @return 两个参数的差 */ public static String sub(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static double mul(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.multiply(b2).doubleValue(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static BigDecimal mul(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static double mul(double v1, double v2, int scale) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return round(b1.multiply(b2).doubleValue(), scale); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static String mul(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到 * 小数点以后10位,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @return 两个参数的商 */ public static double div(double v1, double v2) { return div(v1, v2, DEF_DIV_SCALE); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示表示需要精确到小数点以后几位。 * @return 两个参数的商 */ public static double div(double v1, double v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示需要精确到小数点以后几位 * @return 两个参数的商 */ public static String div(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v1); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static double round(double v, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(Double.toString(v)); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static String round(String v, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(v); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static String remainder(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.remainder(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 BigDecimal * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static BigDecimal remainder(BigDecimal v1, BigDecimal v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } return v1.remainder(v2).setScale(scale, BigDecimal.ROUND_HALF_UP); } /** * 比较大小 * * @param v1 被比较数 * @param v2 比较数 * @return 如果v1 大于v2 则 返回true 否则false */ public static boolean compare(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); int bj = b1.compareTo(b2); boolean res; if (bj > 0) res = true; else res = false; return res; } }原文地址:https://www.cnblogs.com/zhangyinhua/p/11545305.html
Java 开发之 BigDecimal 用法细节详解 一、BigDecimal 概述 Java 在 java.math 包中提供的 API 类 BigDecimal,用来对超过 16 位有效位的数进行精确的运算。双精度浮点型变量 double 可以处理 16 位有效数,但在实际应用中,可能需要对更大或者更小的数进行运算和处理。一般情况下,对于那些不需要准确计算精度的数字,我们可以直接使用 Float 和 Double 处理,但是 Double.valueOf(String) 和 Float.valueOf(String) 会丢失精度。所以开发中,如果我们需要精确计算的结果,则必须使用 BigDecimal 类来操作。BigDecimal所创建的是对象,故我们不能使用传统的 +、-、*、/ 等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法。方法中的参数也必须是 BigDecimal 的对象。构造器是类的特殊方法,专门用来创建对象,特别是带有参数的对象。二、BigDecimal 常用构造函数2.1、常用构造函数// 创建一个具有参数所指定整数值的对象 BigDecimal(int) // 创建一个具有参数所指定双精度值的对象 BigDecimal(double) // 创建一个具有参数所指定长整数值的对象 BigDecimal(long) // 创建一个具有参数所指定以字符串表示的数值的对象 BigDecimal(String)2.2、使用问题分析使用示例:BigDecimal a =new BigDecimal(0.1); System.out.println("a values is:"+a); System.out.println("====================="); BigDecimal b =new BigDecimal("0.1"); System.out.println("b values is:"+b);结果示例:a values is:0.1000000000000000055511151231257827021181583404541015625 ===================== b values is:0.1原因分析:1)参数类型为 double 的构造方法的结果有一定的不可预知性。有人可能认为在 Java 中写入 newBigDecimal(0.1) 所创建的 BigDecimal 正好等于 0.1(非标度值 1,其标度为 1),但是它实际上等于 0.1000000000000000055511151231257827021181583404541015625。这是因为 0.1 无法准确地表示为 double(或者说对于该情况,不能表示为任何有限长度的二进制小数)。这样,传入到构造方法的值不会正好等于 0.1(虽然表面上等于该值)。2)String 构造方法是完全可预知的:写入 newBigDecimal(“0.1”) 将创建一个 BigDecimal,它正好等于预期的 0.1。因此,比较而言, 通常建议优先使用String构造方法。3)当 double 必须用作 BigDecimal 的源时,请注意,此构造方法提供了一个准确转换;它不提供与以下操作相同的结果:先使用 Double.toString(double) 方法,然后使用 BigDecimal(String) 构造方法,将 double 转换为 String。要获取该结果,请使用 static valueOf(double) 方法。三、BigDecimal 常用方法详解3.1、常用方法// BigDecimal 对象中的值相加,返回 BigDecimal 对象 add(BigDecimal) // BigDecimal 对象中的值相减,返回 BigDecimal 对象 subtract(BigDecimal) // BigDecimal 对象中的值相乘,返回 BigDecimal 对象 multiply(BigDecimal) // BigDecimal 对象中的值相除,返回 BigDecimal 对象 divide(BigDecimal) // 将 BigDecimal 对象中的值转换成字符串 toString() // 将 BigDecimal 对象中的值转换成双精度数 doubleValue() // 将 BigDecimal 对象中的值转换成单精度数 floatValue() // 将 BigDecimal 对象中的值转换成长整数 longValue() // 将 BigDecimal 对象中的值转换成整数 intValue()3.2、BigDecimal大小比较java 中对 BigDecimal 比较大小一般用的是 bigdemical 的 compareTo 方法int a = bigdemical.compareTo(bigdemical2)返回结果分析:a = -1,表示bigdemical小于bigdemical2; a = 0,表示bigdemical等于bigdemical2; a = 1,表示bigdemical大于bigdemical2;举例:a大于等于bnew bigdemica(a).compareTo(new bigdemical(b)) >= 0四、BigDecimal 格式化由于 NumberFormat 类的 format() 方法可以使用 BigDecimal 对象作为其参数,可以利用 BigDecimal 对超出 16 位有效数字的货币值,百分值,以及一般数值进行格式化控制。以利用 BigDecimal 对货币和百分比格式化为例。首先,创建 BigDecimal 对象,进行 BigDecimal 的算术运算后,分别建立对货币和百分比格式化的引用,最后利用 BigDecimal 对象作为 format() 方法的参数,输出其格式化的货币值和百分比。NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用 NumberFormat percent = NumberFormat.getPercentInstance(); //建立百分比格式化引用 percent.setMaximumFractionDigits(3); //百分比小数点最多3位 BigDecimal loanAmount = new BigDecimal("15000.48"); //贷款金额 BigDecimal interestRate = new BigDecimal("0.008"); //利率 BigDecimal interest = loanAmount.multiply(interestRate); //相乘 System.out.println("贷款金额:\t" + currency.format(loanAmount)); System.out.println("利率:\t" + percent.format(interestRate)); System.out.println("利息:\t" + currency.format(interest)); 结果:贷款金额: ¥15,000.48 利率: 0.8% 利息: ¥120.00BigDecimal 格式化保留两位小数,不足则补 0:public class NumberFormat { public static void main(String[] s){ System.out.println(formatToNumber(new BigDecimal("3.435"))); System.out.println(formatToNumber(new BigDecimal(0))); System.out.println(formatToNumber(new BigDecimal("0.00"))); System.out.println(formatToNumber(new BigDecimal("0.001"))); System.out.println(formatToNumber(new BigDecimal("0.006"))); System.out.println(formatToNumber(new BigDecimal("0.206"))); } /** * @desc 1.0~1之间的BigDecimal小数,格式化后失去前面的0,则前面直接加上0。 * 2.传入的参数等于0,则直接返回字符串"0.00" * 3.大于1的小数,直接格式化返回字符串 * @param obj传入的小数 * @return */ public static String formatToNumber(BigDecimal obj) { DecimalFormat df = new DecimalFormat("#.00"); if(obj.compareTo(BigDecimal.ZERO)==0) { return "0.00"; }else if(obj.compareTo(BigDecimal.ZERO)>0&&obj.compareTo(new BigDecimal(1))<0){ return "0"+df.format(obj).toString(); }else { return df.format(obj).toString(); } } }结果为:3.44 0.00 0.00 0.00 0.01 0.21五、BigDecimal常见异常5.1、除法的时候出现异常java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result原因分析:通过BigDecimal的divide方法进行除法时当不整除,出现无限循环小数时,就会抛异常:java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.解决方法:divide 方法设置精确的小数点,如:divide(xxxxx,2)六、BigDecimal总结6.1、总结在需要精确的小数计算时再使用 BigDecimal,BigDecimal 的性能比 double 和 float 差,在处理庞大,复杂的运算时尤为明显。故一般精度的计算没必要使用 BigDecimal。尽量使用参数类型为 String 的构造函数。BigDecimal 都是不可变的(immutable)的, 在进行每一次四则运算时,都会产生一个新的对象 ,所以在做加减乘除运算时要记得要保存操作后的值。6.2、工具类推荐package com.vivo.ars.util; import java.math.BigDecimal; /** * 用于高精确处理常用的数学运算 */ public class ArithmeticUtils { //默认除法运算精度 private static final int DEF_DIV_SCALE = 10; /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static double add(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.add(b2).doubleValue(); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @return 两个参数的和 */ public static BigDecimal add(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2); } /** * 提供精确的加法运算 * * @param v1 被加数 * @param v2 加数 * @param scale 保留scale 位小数 * @return 两个参数的和 */ public static String add(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.add(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static double sub(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.subtract(b2).doubleValue(); } /** * 提供精确的减法运算。 * * @param v1 被减数 * @param v2 减数 * @return 两个参数的差 */ public static BigDecimal sub(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2); } /** * 提供精确的减法运算 * * @param v1 被减数 * @param v2 减数 * @param scale 保留scale 位小数 * @return 两个参数的差 */ public static String sub(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.subtract(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static double mul(double v1, double v2) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.multiply(b2).doubleValue(); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @return 两个参数的积 */ public static BigDecimal mul(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static double mul(double v1, double v2, int scale) { BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return round(b1.multiply(b2).doubleValue(), scale); } /** * 提供精确的乘法运算 * * @param v1 被乘数 * @param v2 乘数 * @param scale 保留scale 位小数 * @return 两个参数的积 */ public static String mul(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.multiply(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到 * 小数点以后10位,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @return 两个参数的商 */ public static double div(double v1, double v2) { return div(v1, v2, DEF_DIV_SCALE); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示表示需要精确到小数点以后几位。 * @return 两个参数的商 */ public static double div(double v1, double v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(Double.toString(v1)); BigDecimal b2 = new BigDecimal(Double.toString(v2)); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指 * 定精度,以后的数字四舍五入 * * @param v1 被除数 * @param v2 除数 * @param scale 表示需要精确到小数点以后几位 * @return 两个参数的商 */ public static String div(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v1); return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static double round(double v, int scale) { if (scale < 0) { throw new IllegalArgumentException("The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(Double.toString(v)); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).doubleValue(); } /** * 提供精确的小数位四舍五入处理 * * @param v 需要四舍五入的数字 * @param scale 小数点后保留几位 * @return 四舍五入后的结果 */ public static String round(String v, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b = new BigDecimal(v); return b.setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static String remainder(String v1, String v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); return b1.remainder(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString(); } /** * 取余数 BigDecimal * * @param v1 被除数 * @param v2 除数 * @param scale 小数点后保留几位 * @return 余数 */ public static BigDecimal remainder(BigDecimal v1, BigDecimal v2, int scale) { if (scale < 0) { throw new IllegalArgumentException( "The scale must be a positive integer or zero"); } return v1.remainder(v2).setScale(scale, BigDecimal.ROUND_HALF_UP); } /** * 比较大小 * * @param v1 被比较数 * @param v2 比较数 * @return 如果v1 大于v2 则 返回true 否则false */ public static boolean compare(String v1, String v2) { BigDecimal b1 = new BigDecimal(v1); BigDecimal b2 = new BigDecimal(v2); int bj = b1.compareTo(b2); boolean res; if (bj > 0) res = true; else res = false; return res; } }原文地址:https://www.cnblogs.com/zhangyinhua/p/11545305.html -
Jpa进阶,使用 Specification 进行高级查询 前言上一篇文章主要讲了 Jpa 的简单使用,而在实际项目中并不能满足我们的需求。如对多张表的关联查询,以及查询时需要的各种条件,这个时候你可以使用自定义 SQL 语句,但是Jpa并不希望我们这么做,于是就有了一个扩展:使用 Specification 进行查询修改相应代码1、修改 User.class代码用的上一篇文章的,这里在 User 类中进行扩展,待会查询时会用到@Entity @Table(name = "user") public class User { //部分代码略 /** * 加上该注解,在保存该实体时,Jpa将为我们自动设置上创建时间 */ @CreationTimestamp private Timestamp createTime; /** * 加上该注解,在保存或者修改该实体时,Jpa将为我们自动创建时间或更新日期 */ @UpdateTimestamp private Timestamp updateTime; /** * 关联角色,测试多表查询 */ @ManyToOne @JoinColumn(name = "role_id") private Role role; //部分代码略 }2、新增Role.class@Entity @Table(name = "role") public class Role { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(unique = true,nullable = false) private String name; //get set略 }3、修改UserRepository要使用 Specification,需要继承 JpaSpecificationExecutor 接口,修改后的代码如下public interface UserRepo extends JpaRepository<User,Long>, JpaSpecificationExecutor { }4、查看 JpaSpecificationExecutor 源码Specification 是 Spring Data JPA 提供的一个查询规范,这里所有的操作都是围绕 Specification 来进行public interface JpaSpecificationExecutor<T> { Optional<T> findOne(@Nullable Specification<T> var1); List<T> findAll(@Nullable Specification<T> var1); Page<T> findAll(@Nullable Specification<T> var1, Pageable var2); List<T> findAll(@Nullable Specification<T> var1, Sort var2); long count(@Nullable Specification<T> var1); }封装查询Service我这里简单做了下简单封装,编写 UserQueryService.class@Service public class UserQueryService { @Autowired private UserRepo userRepo; /** * 分页加高级查询 */ public Page queryAll(User user, Pageable pageable , String roleName){ return userRepo.findAll(new UserSpec(user,roleName),pageable); } /** * 不分页 */ public List queryAll(User user){ return userRepo.findAll(new UserSpec(user)); } class UserSpec implements Specification<User>{ private User user; private String roleName; public UserSpec(User user){ this.user = user; } public UserSpec(User user,String roleName){ this.user = user; this.roleName = roleName; } @Override public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) { List<Predicate> list = new ArrayList<Predicate>(); /** * 左连接,关联查询 */ Join<Role,User> join = root.join("role",JoinType.LEFT); if(!StringUtils.isEmpty(user.getId())){ /** * 相等 */ list.add(cb.equal(root.get("id").as(Long.class),user.getId())); } if(!StringUtils.isEmpty(user.getUsername())){ /** * 模糊 */ list.add(cb.like(root.get("username").as(String.class),"%"+user.getUsername()+"%")); } if(!StringUtils.isEmpty(roleName)){ /** * 这里的join.get("name"),就是对应的Role.class里面的name */ list.add(cb.like(join.get("name").as(String.class),"%"+roleName+"%")); } if(!StringUtils.isEmpty(user.getCreateTime())){ /** * 大于等于 */ list.add(cb.greaterThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getCreateTime())); } if(!StringUtils.isEmpty(user.getUpdateTime())){ /** * 小于等于 */ list.add(cb.lessThanOrEqualTo(root.get("createTime").as(Timestamp.class),user.getUpdateTime())); } Predicate[] p = new Predicate[list.size()]; return cb.and(list.toArray(p)); } } }查询测试1、新增测试数据 @Test public void test3() { /** * 新增角色 */ Role role = new Role(); role.setName("测试角色"); role = roleRepo.save(role); /** * 新增并绑定角色 */ User user = new User("小李",20,"男",role); User user1 = new User("小花",21,"女",role); userRepo.save(user); userRepo.save(user1); }查看数据都已经新增成功了,并且 createTime 和 updateTime 也帮我们加上了2、简单查询 @Test public void Test4(){ /** * 添加查询数据,模糊查询用户名 */ User user = new User(); user.setUsername("花"); List<User> users = userQueryService.queryAll(user); users.forEach(user1 -> { System.out.println(user1.toString()); }); }运行结果如下3、分页+关联查询 @Test public void test5() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> users = userQueryService.queryAll(new User(),pageable,"测试角色"); System.out.println("总数据条数:"+users.getTotalElements()); System.out.println("总页数:"+users.getTotalPages()); System.out.println("当前页数:"+users.getNumber()); users.forEach(user1 -> { System.out.println(user1.toString()); }); } }通过角色的名称查询用户,运行结果如下
-
JPA入门,Spring Boot 整合 JPA 操作数据库 简单了解Jpa(java Persistence API,java持久化 api),它定义了对象关系映射(ORM)以及实体对象持久化的标准接口。在 Spring boot中 JPA 是依靠 Hibernate才得以实现对的,Hibernate 在 3.2 版本中对 JPA 的实现有了完全的支持。Spring Boot 整合 JPA 可使开发者用极简的代码实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!添加依赖#这里添加 Jpa 和 Mysql 的依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>开发Jpa编写实体类定义用户实体类 User//@Entity 表明这个是一个实体类 @Entity //指定表名 @Table(name = "user") public class User { /** * 表明这个字段是主键,并且ID是自增的 */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** * 这样则表示该属性,在数据库中的名称是 username,并且使唯一的且不能为空的 */ @Column(name = "username",unique = true,nullable = false) private String username; private Integer age; private String sex; //get set略 }配置文件说明Spring Boot 配置文件 application.yml 内容如下server: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/jpa username: root password: 123456 jpa: hibernate: #注入方式 ddl-auto: update naming: #Hibernate 命名策略,这里修改下 physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl properties: hibernate: #数据库方言 dialect: org.hibernate.dialect.MySQL5InnoDBDialectddl-auto属性说明常用属性: 自动创建|更新|验证数据库表结构。 **create:** 每次启动时都会删除上一次的生成的表,然后根据你的实体类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。 **create-drop :** 每次加载 hibernate 时根据 model 类生成表,但是 sessionFactory 一关闭,表就自动删除。 **update:** 最常用的属性,第一次加载启动时根据实体类会自动建立起表的结构(前提是先建立好数据库),以后以后再次启动时会根据实体类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。 **validate :** 每次应用启动时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。这里我们使用 update,让应用启动时自动给我们生成 User 表基础操作1、编写 UserRepo 继承 JpaRepositoryimport me.zhengjie.domain.User; import org.springframework.data.jpa.repository.JpaRepository; public interface UserRepo extends JpaRepository<User,Long> { }2、使用默认方法在 test 目录中,新建 UserTests @RunWith(SpringRunner.class) @SpringBootTest public class UserTests { @Autowired private UserRepo userRepo; @Test public void test1() { User user=new User(); //查询全部 List<User> userList = userRepo.findAll(); //根据ID查询 Optional<User> userOptional = userRepo.findById(1L); //保存,成功后会返回成功后的结果 user = userRepo.save(user); //删除 userRepo.delete(user); //根据ID删除 userRepo.deleteById(1L); //计数 Long count = userRepo.count(); //验证是否存在 Boolean b = userRepo.existsById(1l); } } 自定义简单查询自定义的简单查询就是根据方法名来自动生成 SQL,主要的语法是 findXXBy, readAXXBy, queryXXBy, countXXBy, getXXBy 后面跟属性名称:public interface UserRepo extends JpaRepository<User,Long> { /** * 根据 username 查询 * @param username * @return */ User findByUsername(String username); /** * 根据 username 和 age 查询 * @param username * @param age * @return */ User findByUsernameAndAge(String username,Integer age); }具体的关键字,使用方法和生产成 SQL 如下表所示KeywordSampleJPQL snippetAndfindByLastnameAndFirstname… where x.lastname = ?1 and x.firstname = ?2OrfindByLastnameOrFirstname… where x.lastname = ?1 or x.firstname = ?2Is,EqualsfindByFirstnameIs,findByFirstnameEquals… where x.firstname = ?1BetweenfindByStartDateBetween… where x.startDate between ?1 and ?2LessThanfindByAgeLessThan… where x.age < ?1LessThanEqualfindByAgeLessThanEqual… where x.age ⇐ ?1GreaterThanfindByAgeGreaterThan… where x.age > ?1GreaterThanEqualfindByAgeGreaterThanEqual… where x.age >= ?1AfterfindByStartDateAfter… where x.startDate > ?1BeforefindByStartDateBefore… where x.startDate < ?1IsNullfindByAgeIsNull… where x.age is nullIsNotNull,NotNullfindByAge(Is)NotNull… where x.age not nullLikefindByFirstnameLike… where x.firstname like ?1NotLikefindByFirstnameNotLike… where x.firstname not like ?1StartingWithfindByFirstnameStartingWith… where x.firstname like ?1 (parameter bound with appended %)EndingWithfindByFirstnameEndingWith… where x.firstname like ?1 (parameter bound with prepended %)ContainingfindByFirstnameContaining… where x.firstname like ?1 (parameter bound wrapped in %)OrderByfindByAgeOrderByLastnameDesc… where x.age = ?1 order by x.lastname descNotfindByLastnameNot… where x.lastname <> ?1InfindByAgeIn(Collection ages)… where x.age in ?1NotInfindByAgeNotIn(Collection age)… where x.age not in ?1TRUEfindByActiveTrue()… where x.active = trueFALSEfindByActiveFalse()… where x.active = falseIgnoreCasefindByFirstnameIgnoreCase… where UPPER(x.firstame) = UPPER(?1)分页查询Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable);Pageable 是 spring 封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则@Test public void test2() { //页码,Pageable中默认是从0页开始 int page = 0; //每页的个数 int size = 10; Sort sort = new Sort(Sort.Direction.DESC,"id"); Pageable pageable = PageRequest.of(page,size,sort); Page<User> list = userRepo.findAll(pageable); }限制查询有时候我们只需要查询前N个元素 /** * 限制查询 */ List<User> queryFirstByAge(Integer age); List<User> queryFirst10ByAge(Integer age);自定义SQL如果项目中由于某些原因 Jpa 自带的已经满足不了我们的需求了,这个时候我们就可以自定义的 SQL 来查询,只需要在 SQL 的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上 @Modifying /** * 自定义SQL,nativeQuery = true,表明使用原生sql */ @Modifying @Query(value = "update User u set u.userName = ?1 where u.id = ?2",nativeQuery = true) void modifyUsernameById(String userName, Long id); @Modifying @Query(value = "delete from User where id = ?1",nativeQuery = true) void deleteByUserId(Long id); @Query(value = "select u from User u where u.id = ?1",nativeQuery = true) User findByUserId(Long id);本文主要讲解了 Jpa 的一些简单的操作,下篇文章将讲解 Jpa 如何使用 Specification 实现复杂的查询,如多表查询,模糊查询,日期的查询等
-
vue 中 input 限制只能输入数字,允许正数与负数 vue 的 input 中, 限制只能输入正数与负数,完整代码如下:<template> <el-input v-model="number" @input="onlyNbr1" @change="onlyNbr2"/> </template> <script> data() { return { number: null } }, methods: { onlyNbr1(ipt) { let data = String(ipt) const char = data.charAt(0) // 先把非数字的都替换掉 data = data.replace(/[^\d]/g, '') // 如果第一位是负号,则允许添加 if (char === '-') { data = '-' + data } this.number = data }, onlyNbr2() { const data = String(this.number) // 如果只有一个负数,那么替换为 null console.log(data === '-') if (data === '-') { this.number = null } } } }如果有更好的实现方式,欢迎评论讨论。
-
记 Spring Boot 项目无法插入 utf8mb4mb4 编码数据的问题 今天同步微信公众号粉丝数据的时候,发现其中一条插入失败了,错误信息如下:java.sql.SQLException: Incorrect string value: '\xF0\x9F\x87\xB1 \xF0...' for column 'nickname' at row 1异常排查检查后发现粉丝的昵称是特殊字符: ? ? ? 检查数据库后发现编码为:utf8mb4,修改数据库编码为 utf8mb4mb4 后再次测试,依旧出错。通过项目日志,获取到具体 Sql 代码INSERT INTO wx_user ( open_id, nickname, sex, head_img_url, country, province, city, remark, subscribe, subscribe_time ) VALUES ( '**', '? ? ? ', 1, '', '**', '**', '**', '', 1, '2021-07-15 16:03:00' ) 手动执行 Sql 代码,居然插入成功了...解决办法通过上面的排查,排除掉了数据库的问题,通过查阅资料,发现可以在 application.yml 的 Durid 参数中设置客户端连接数据库编码spring: datasource: driverClassName: com.mysql.jdbc.Driver password: ** url: jdbc:log4jdbc:mysql://127.0.0.1:3306/**?useUnicode=true&characterEncoding=utf8mb4&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true username: root druid: # 兼容 utf8mb4mb4 编码格式 connection-init-sqls: set names utf8mb4mb4重启项目,再次尝试,同步成功~
-
全局ID生成器:SpringBoot2.x 集成百度 uidgenerator 因为升级 使用springboot2.x java 11 的关系,根据官方文档和网上其他作者配置的怎么也配置不成功,最后自己一步一步升级引入依赖,修改增加接口注入来源,最后成功。升级成功后的源码地址:https://github.com/foxiswho/java-spring-boot-uid-generator-baidu部分升级说明这里的升级,是升级 官方 代码依赖官方代码地址:https://github.com/baidu/uid-generator升级spring boot 版本: 2.0.7.RELEASE升级 mybatis,mybatis-spring 版本升级 mysql-connector-java 版本:8.0.12升级 junit 版本创建数据库存导入官网数据库SQL https://github.com/baidu/uid-generator/blob/master/src/main/scripts/WORKER_NODE.sql也就是一张表我这里是在 demo 库中,创建了这张表DROP TABLE IF EXISTS WORKER_NODE; CREATE TABLE WORKER_NODE ( ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id', HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name', PORT VARCHAR(64) NOT NULL COMMENT 'port', TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER', LAUNCH_DATE DATE NOT NULL COMMENT 'launch date', MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time', CREATED TIMESTAMP NOT NULL COMMENT 'created time', PRIMARY KEY(ID) ) COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;如果报错,基本上是时间问题,因为mysql 低版本控制比较严格,解决方法有多种方式方式一:直接把TIMESTAMP改成DATETIME 即可方式二:执行SQL 语句前先执行:set sql_mode="NO_ENGINE_SUBSTITUTION";mysql 配置信息更改因为升级到8.x ,配置文件部分也要跟着修改 uid-generator 下,测试文件夹下的资源包 uid/mysql.properties以下修改为mysql.driver=com.mysql.cj.jdbc.Driver修改完成后,配置好数据库相关参数,这样单元测试即可执行成功案例计划将全局生成唯一ID作为一个服务提供者,供其他微服务使用调用这里创建了一个项目,项目中包含两个子项目一个是 uid-generator 官方本身,当然你也可以不需要放到本项目中,直接使用官方的自行打包即可,一个是 uid-provider 服务提供者以下说明的主要是服务提供者创建 子项目 uid-provider如何创建 略POM配置文件如下<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>java-spring-boot-uid-generator-baidu</artifactId> <groupId>com.foxwho.demo</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>uid-provider</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency> <!--for Mysql--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> <version>8.0.12</version> </dependency> <!-- druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.16</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> <optional>true</optional> </dependency> <dependency> <groupId>com.foxwho.demo</groupId> <artifactId>uid-generator</artifactId> <version>1.0-SNAPSHOT</version> </dependency> </dependencies> </project>复制 mapper先在 uid-provider 项目资源包路径下创建 mapper 文件夹,然后到官方 uid-generator 资源包路径下 META-INF/mybatis/mapper/WORKER_NODE.xml 复制 WORKER_NODE.xml 文件,粘贴到该文件夹 mapper 内cache id 配置文件先在 uid-provider 项目资源包路径下创建 uid 文件夹,然后到官方 uid-generator 测试 [注意:这里是测试资源包] 资源包路径下 uid/cached-uid-spring.xml 复制 cached-uid-spring.xml 文件,粘贴到该文件夹 uid 内最后根据需要 配置参数,可以看官方说明创建 spring boot 启动入口主要就是加上注解 @MapperScan("com.baidu.fsg.uid") 让 mybatis 能扫描到 Mapper 类的包的路径package com.foxwho.demo; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.boot.builder.SpringApplicationBuilder; @SpringBootApplication @MapperScan("com.baidu.fsg.uid") public class ConsumerApplication { public static void main(String[] args) { new SpringApplicationBuilder(ConsumerApplication.class).run(args); } }创建配置package com.foxwho.demo.config; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.ImportResource; @Configuration @ImportResource(locations = { "classpath:uid/cached-uid-spring.xml" }) public class UidConfig { }创建服务接口package com.foxwho.demo.service; import com.baidu.fsg.uid.UidGenerator; import org.springframework.stereotype.Service; import javax.annotation.Resource; @Service public class UidGenService { @Resource(name = "cachedUidGenerator") private UidGenerator uidGenerator; public long getUid() { return uidGenerator.getUID(); } }主要说明一下 @Resource(name = "cachedUidGenerator") 以往错误都是少了这里,没有标明注入来源控制器package com.foxwho.demo.controller; import com.foxwho.demo.service.UidGenService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class UidController { @Autowired private UidGenService uidGenService; @GetMapping("/uidGenerator") public String UidGenerator() { return String.valueOf(uidGenService.getUid()); } @GetMapping("/") public String index() { return "index"; } }项目配置文件server.port=8080 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver mybatis.mapper-locations=classpath:mapper/*.xml mybatis.configuration.map-underscore-to-camel-case=true启动项目从启动入口,启动,然后访问浏览器http://localhost:8080/uidGenerator页面输出13128615512260612原文地址:https://foxwho.blog.csdn.net/article/details/90200602
-
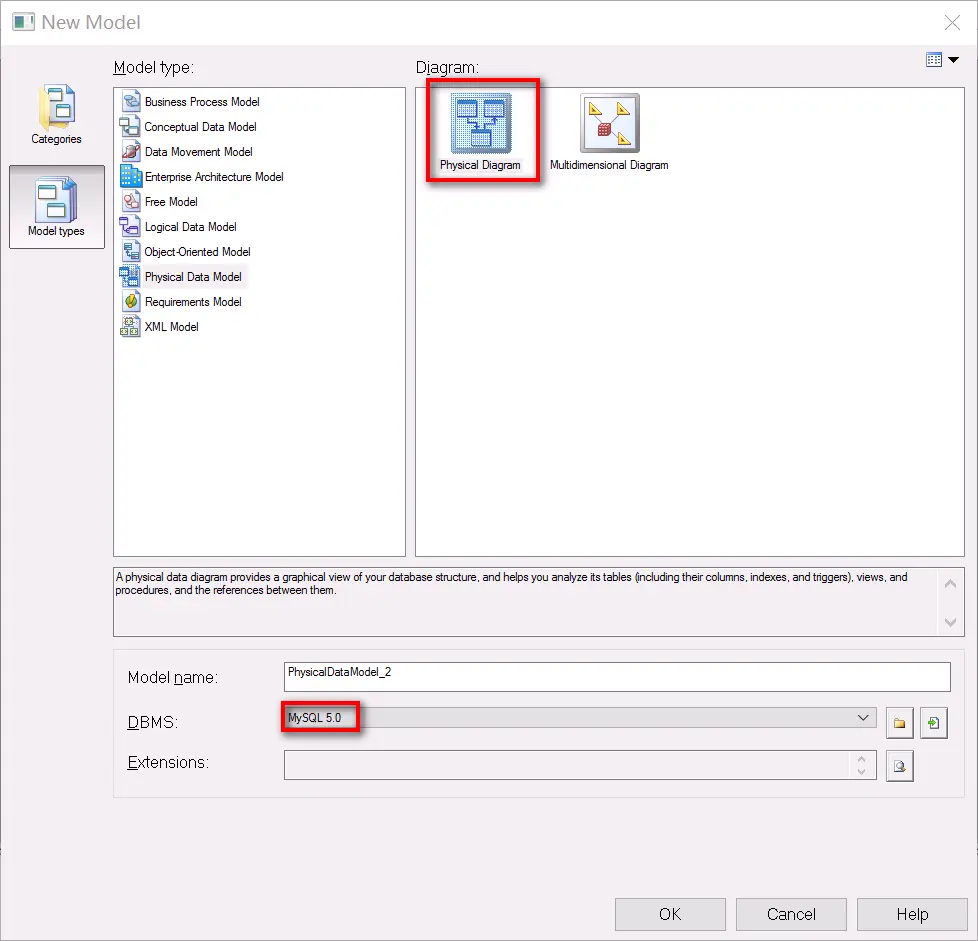
PowerDesigner 连接 MySQL 与生成逆向工程图 最近想梳理公司项目的表间关系,从项目后台管理系统的操作入手,以及代码的hibernate注解入手,都不算特别尽人意,于是最后还是鼓捣了一下PowerDesigner的逆向工程图,这样更直观一些。想着以后不论项目切换或者接手的时候肯定是用得上的,所以在这里也记录一下,毕竟,好记性不如烂笔头,更何况我这还不是好记性。看网上有个哥们说他已经是三次忘了步骤了,所以我吸取教训赶紧第一次就记录下来。1、MySQL数据库连接(JDBC方式)JDBC的配置方式需要一些基础的环境和准备,但是也很简单,无非也就是JDK和mysql的连接jar包,这里不再展开阐述。1.1 新建一个pdm,dbms选择mysql1.2 Database - Connect 选择数据库连接1.3 配置连接信息数据库连接这里是通过一个配置文件来获取连接信息的,首次的话因为没有,所以我们需要选择Configure进行配置。1.4 填写配置信息如图,选择添加数据库资源,出现如上,相关说明如下:Connection profile name:JDBC配置文件名称,可随意填写Directory:配置文件保存路径Description:配置文件描述,可根据实际用途填写Connection type:连接方式,这里我们选择JDBCDBMS type:数据库类型,提供大部分主流数据库选择,我们选择MySQLUser name:登录数据库的用户名JDBC driver class:指定驱动类,使用默认的com.mysql.jdbc.DriverJDBC connection URL:连接URL,格式 jdbc:mysql://ServerIP/Hostname:port/databaseJDBC driver jar files:指定连接的jar包路径1.5连接测试和配置保存如图填写信息完成后,点击左下角的 Test Connection,出现成功提示则说明连接可行:如果测试连接不通过,且出现 Non SQL Error : Could not load class com.mysql.jdbc.Drive 的错误,而指定的jar包没有问题,那么是因为PowerDesigner无法找到驱动所产生的。解决办法是配置系统的classpath路径,指定jar包路径就好了。成功连接后,我们一路确定下去把这个配置文件进行保存,最终你可以在你指定的文件夹(该目录没有限制,自定义一个目录即可,此处我是建立在安装文件下的一个userConf文件夹内)中看到这个保存好的文件:2、从已有数据库中的表进行逆向工程图2.1 菜单选择,从数据库更新模型2.2 选择数据库连接配置文件2.3 选择涉及的数据库和想要导出的表2.4 大功告成原文链接:https://www.cnblogs.com/deng-cc/p/6824946.html
-
Spring 的 Controller 是单例还是多例?怎么保证并发的安全? 答案如下controller 默认是单例的,不要使用非静态的成员变量,否则会发生数据逻辑混乱。正因为单例所以不是线程安全的。我们下面来简单的验证下:package com.riemann.springbootdemo.controller; import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; /** * @author riemann * @date 2019/07/29 22:56 */ @Controller public class ScopeTestController { private int num = 0; @RequestMapping("/testScope") public void testScope() { System.out.println(++num); } @RequestMapping("/testScope2") public void testScope2() { System.out.println(++num); } }我们首先访问 http://localhost:8080/testScope,得到的答案是1;然后我们再访问 http://localhost:8080/testScope2,得到的答案是 2。得到的不同的值,这是线程不安全的。接下来我们再来给 controller 增加作用多例 @Scope("prototype")package com.riemann.springbootdemo.controller; import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; /** * @author riemann * @date 2019/07/29 22:56 */ @Controller @Scope("prototype") public class ScopeTestController { private int num = 0; @RequestMapping("/testScope") public void testScope() { System.out.println(++num); } @RequestMapping("/testScope2") public void testScope2() { System.out.println(++num); } }我们依旧首先访问 http://localhost:8080/testScope,得到的答案是1;然后我们再访问 http://localhost:8080/testScope2,得到的答案还是 1。相信大家不难发现 :单例是不安全的,会导致属性重复使用。解决方案1、不要在 controller 中定义成员变量。2、万一必须要定义一个非静态成员变量时候,则通过注解@Scope(“prototype”),将其设置为多例模式。3、在 Controller 中使用 ThreadLocal 变量补充说明spring bean作用域有以下5个:1、singleton:单例模式,当 spring 创建 applicationContex t容器的时候,spring 会欲初始化所有的该作用域实例,加上 lazy-init 就可以避免预处理;2、prototype:原型模式,每次通过 getBean 获取该 bean 就会新产生一个实例,创建后 spring 将不再对其管理;下面是在web项目下才用到的3、request:搞 web 的大家都应该明白 request 的域了吧,就是每次请求都新产生一个实例,和 prototype 不同就是创建后,接下来的管理,spring 依然在监听;4、session:每次会话,同上;5、global session:全局的 web 域,类似于 servlet 中的 application。原文地址:https://blog.csdn.net/riemann_/article/details/97698560
-
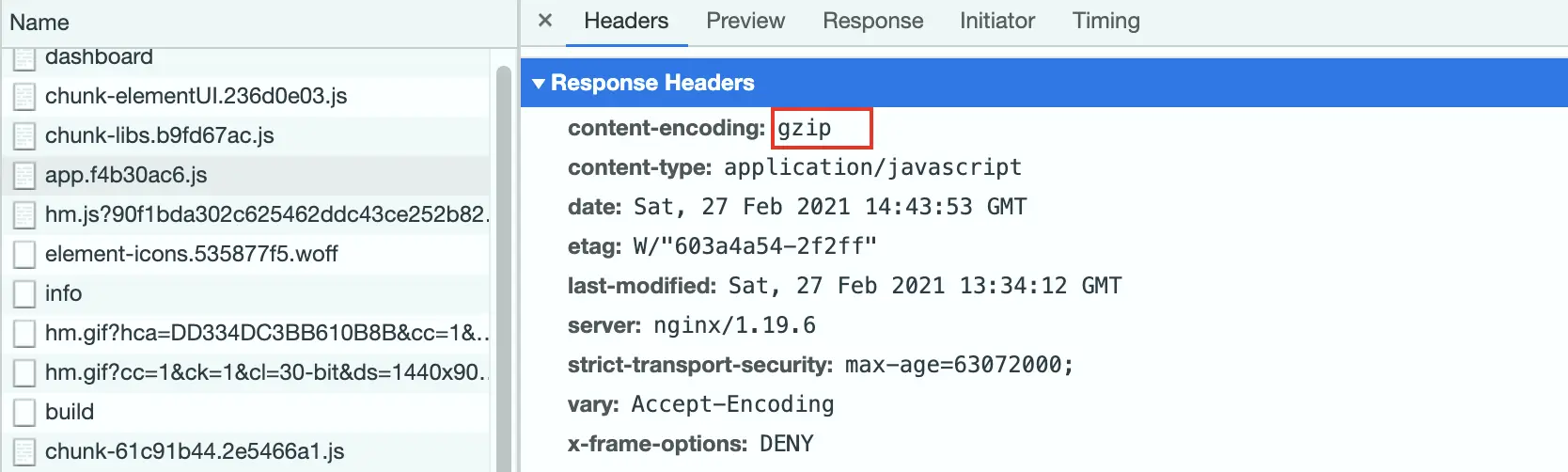
利用 Nginx 的 Gzip 模块解决 Vue 首屏加载缓慢的问题 通过 Nginx 的 Gize 模块拦截请求,并且对相应的资源进行压缩,已达到减少文件体积加快文件访问速度的目的,使用 Nginx 的 Gizp 模块不需要重新编译,直接开启即可。基本配置在 server 中加入如下代码# 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 6; # 需要压缩哪些响应类型的资源,缺少的类型自己补。 gzip_types text/plain application/javascript application/x-javascript text/javascript text/css application/xml; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 设置gzip压缩针对的HTTP协议版本,没做负载的可以不用 # gzip_http_version 1.0;查看效果在 response headers 中的 Content-Encoding 是 gzip 就代表开启成功前后对比未开启 Gzip 的文件大小与加载速度开启 Gzip 后的文件大小与加载速度前后速度提升明显完整配置附上完整的 Nginx https + Gzip 配置server { listen 443 ssl http2; server_name el-admin.xin www.el-admin.xin; # 证书配置 ssl_certificate /etc/nginx/cert/el-admin-xin/el-admin.xin_chain.crt; ssl_certificate_key /etc/nginx/cert/el-admin-xin/el-admin.xin_key.key; # DHE密码器的Diffie-Hellman参数,需要openssl手动生成 # openssl命令:openssl dhparam -dsaparam -out /home/nginx/cert/el-admin-vip/dhparam.pem 4096 ssl_dhparam /etc/nginx/cert/el-admin-xin/dhparam.pem; # 开启OCSP Stapling,由服务器验证证书在线状态,提高TLS握手效率 ssl_stapling on; ssl_stapling_verify on; # 开启HSTS,缓存http重定向到https,以防止中间人攻击 add_header Strict-Transport-Security "max-age=63072000;" always; # 开启TLS False Start ssl_prefer_server_ciphers on; # 中等兼容程度,Mozilla推荐配置 ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384; # 中等兼容程度,Mozilla推荐配置 ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # 由客户端保存加密后的session信息 ssl_session_tickets on; # 缓存SSL ssl_session_cache shared:SSL:10m; ssl_session_timeout 1d; # 长链接 keepalive_timeout 70; #减少点击劫持,禁止在iframe中加载 add_header X-Frame-Options DENY; # 开启gzip gzip on; # 低于1kb的资源不压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 gzip_buffers 4 16k; # 压缩级别【1-9】,越大压缩率越高,同时消耗cpu资源也越多,建议设置在4左右。 gzip_comp_level 4; # 需要压缩哪些响应类型的资源,缺少自己补。 gzip_types text/css text/javascript application/javascript; # 配置禁用gzip条件,支持正则。此处表示ie6及以下不启用gzip(因为ie低版本不支持) gzip_disable "MSIE [1-6]\."; # 是否添加“Vary: Accept-Encoding”响应头, gzip_vary on; # 根目录 location / { root /usr/share/nginx/html/eladmin/dist; index index.html; try_files $uri $uri/ @router; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } location @router { rewrite ^.*$ /index.html last; } } server { listen 80; server_name el-admin.xin; return 301 https://el-admin.xin$request_uri; }
-
@Autowire 和 @Resource 注解的区别与使用的正确姿势 今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?@Autowire private JdbcTemplate jdbcTemplate;提示的警告信息Field injection is not recommended Inspection info: Spring Team recommends: "Always use constructor based dependency injection in your beans. Always use assertions for mandatory dependencies". 这段是Spring工作组的建议,大致翻译一下: 属性字段注入的方式不推荐,检查到的问题是:Spring团队建议:"始终在bean中使用基于构造函数的依赖项注入, 始终对强制性依赖项使用断言如图:Field注入警告注入方式虽然当前有关Spring Framework(5.0.3)的文档仅定义了两种主要的注入类型,但实际上有三种:基于构造函数的依赖注入public class UserServiceImpl implents UserService{ private UserDao userDao; @Autowire public UserServiceImpl(UserDao userDao){ this.userDao = userDao; } }基于Setter的依赖注入public class UserServiceImpl implents UserService{ private UserDao userDao; @Autowire public serUserDao(UserDao userDao){ this.userDao = userDao; } }基于字段的依赖注入public class UserServiceImpl implents UserService{ @Autowire private UserDao userDao; }基于字段的依赖注入方式会在Idea当中吃到黄牌警告,但是这种使用方式使用的也最广泛,因为简洁方便.您甚至可以在一些Spring指南中看到这种注入方法,尽管在文档中不建议这样做.(有点执法犯法的感觉)如图基于字段的依赖注入缺点1、对于有final修饰的变量不好使Spring的IOC对待属性的注入使用的是set形式,但是final类型的变量在调用class的构造函数的这个过程当中就得初始化完成,这个是基于字段的依赖注入做不到的地方.只能使用基于构造函数的依赖注入的方式2、掩盖单一职责的设计思想我们都知道在OOP的设计当中有一个单一职责思想,如果你采用的是基于构造函数的依赖注入的方式来使用Spring的IOC的时候,当你注入的太多的时候,这个构造方法的参数就会很庞大,类似于下面.当你看到这个类的构造方法那么多参数的时候,你自然而然的会想一下:这个类是不是违反了单一职责思想?.但是使用基于字段的依赖注入不会让你察觉,你会很沉浸在@Autowire当中public class VerifyServiceImpl implents VerifyService{ private AccountService accountService; private UserService userService; private IDService idService; private RoleService roleService; private PermissionService permissionService; private EnterpriseService enterpriseService; private EmployeeService employService; private TaskService taskService; private RedisService redisService; private MQService mqService; public SystemLogDto(AccountService accountService, UserService userService, IDService idService, RoleService roleService, PermissionService permissionService, EnterpriseService enterpriseService, EmployeeService employService, TaskService taskService, RedisService redisService, MQService mqService) { this.accountService = accountService; this.userService = userService; this.idService = idService; this.roleService = roleService; this.permissionService = permissionService; this.enterpriseService = enterpriseService; this.employService = employService; this.taskService = taskService; this.redisService = redisService; this.mqService = mqService; } }3、与Spring的IOC机制紧密耦合当你使用基于字段的依赖注入方式的时候,确实可以省略构造方法和setter这些个模板类型的方法,但是,你把控制权全给Spring的IOC了,别的类想重新设置下你的某个注入属性,没法处理(当然反射可以做到).本身Spring的目的就是解藕和依赖反转,结果通过再次与类注入器(在本例中为Spring)耦合,失去了通过自动装配类字段而实现的对类的解耦,从而使类在Spring容器之外无效.4、隐藏依赖性当你使用Spring的IOC的时候,被注入的类应当使用一些public类型(构造方法,和setter类型方法)的方法来向外界表达:我需要什么依赖.但是基于字段的依赖注入的方式,基本都是private形式的,private把属性都给封印到class当中了.5、无法对注入的属性进行安检基于字段的依赖注入方式,你在程序启动的时候无法拿到这个类,只有在真正的业务使用的时候才会拿到,一般情况下,这个注入的都是非null的,万一要是null怎么办,在业务处理的时候错误才爆出来,时间有点晚了,如果在启动的时候就暴露出来,那么bug就可以很快得到修复(当然你可以加注解校验).如果你想在属性注入的时候,想根据这个注入的对象操作点东西,你无法办到.我碰到过的例子:一些配置信息啊,有些人总是会配错误,等到了自己测试业务阶段才知道配错了,例如线程初始个数不小心配置成了3000,机器真的是狂叫啊!这个时候就需要再某些Value注入的时候做一个检测机制.结论通过上面,我们可以看到,基于字段的依赖注入方式有很多缺点,我们应当避免使用基于字段的依赖注入.推荐的方法是使用基于构造函数和基于setter的依赖注入.对于必需的依赖项,建议使用基于构造函数的注入,以使它们成为不可变的,并防止它们为null。对于可选的依赖项,建议使用基于Setter的注入后记翻译自 field-injection-is-not-recommended,加入了自己的白话理解!原文链接:https://juejin.cn/post/6844904064212271117
-
EL-ADMIN 邮箱配置之使用 QQ 邮箱发送邮件 EL-ADMIN 配置邮箱后,发送邮件提示:邮箱发送邮件失败:AuthenticationFailedExceptionissues 地址:https://github.com/elunez/eladmin/issues/571修复步骤1、在QQ邮箱中 开启 IMAP/SMTP服务,获取独立密码2、在邮件工具里面配置邮箱信息参数说明1、发件人用户名:用户收信时显示的发件人名称2、邮箱密码:QQ邮箱需要为SMTP服务单独设置密码3、QQ 邮箱的 SMTP 地址:smtp.qq.com4、SMTP 使用默认的 465 即可修改代码定位到:eladmin-tools/src/main/java/me/zhengjie/service/impl/EmailServiceImpl.java修改第 72 行// 设置用户 String user = emailConfig.getFromUser().split("@")[0]; account.setUser(user);重新启动项目即可